Apsveriet binomālo sadalījumu, aprēķiniet to paredzamā vērtība, dispersija, režīms. Izmantojot MS EXCEL funkciju BINOM.DIST(), uzzīmēsim sadalījuma funkcijas un varbūtības blīvuma grafikus. Novērtēsim sadalījuma parametru p, sadalījuma matemātisko cerību un standartnovirzi. Apsveriet arī Bernulli sadalījumu.
Definīcija. Lai viņi tiek turēti n testi, kuros katrā var notikt tikai 2 notikumi: notikums "veiksmīgs" ar varbūtību lpp vai notikums "neveiksme" ar varbūtību q =1-p (tā sauktais Bernulli shēma,Bernulliizmēģinājumi).
Varbūtība iegūt tieši x panākumi šajos n testi ir vienādi ar:
Panākumu skaits izlasē x ir nejaušs mainīgais, kam ir Binomiālais sadalījums(Angļu) Binomiālsizplatīšana) lpp un n – ir šī sadalījuma parametri.
Atgādiniet to, lai pieteiktos Bernulli shēmas un attiecīgi binomiālais sadalījums, ir jāievēro šādi nosacījumi:
- katram izmēģinājumam ir jābūt tieši diviem rezultātiem, kurus nosacīti sauc par "veiksmi" un "neveiksmi".
- katra testa rezultāts nedrīkst būt atkarīgs no iepriekšējo testu rezultātiem (testa neatkarība).
- panākumu līmenis lpp jābūt nemainīgam visos testos.
Binomiālais sadalījums programmā MS EXCEL
Programmā MS EXCEL, sākot no 2010. gada versijas, paredzēta ir funkcija BINOM.DIST() , nosaukums angļu valodā- BINOM.DIST(), kas ļauj aprēķināt varbūtību, ka izlase būs precīzi X"panākumi" (t.i. varbūtības blīvuma funkcija p(x), skatiet formulu iepriekš), un integrālā sadales funkcija(varbūtība, ka paraugam būs x vai mazāk "veiksmes", ieskaitot 0).
Pirms MS EXCEL 2010 programmā EXCEL bija funkcija BINOMDIST(), kas arī ļauj aprēķināt sadales funkcija un varbūtības blīvums p(x). BINOMDIST() ir atstāts programmā MS EXCEL 2010, lai nodrošinātu saderību.
Piemēra failā ir grafiki varbūtības sadalījuma blīvums un .

Binomiālais sadalījums ir apzīmējums B (n ; lpp) .
Piezīme: Ēkai integrālā sadales funkcija ideāli piemērots diagrammas veids Grafiks, priekš sadalījuma blīvums – Histogramma ar grupēšanu. Plašāku informāciju par diagrammu veidošanas iespējām lasiet rakstā Galvenie diagrammu veidi.
Piezīme: Formulu rakstīšanas ērtībai piemēru failā ir izveidoti parametru nosaukumi Binomiālais sadalījums: n un p.

Piemēra failā ir parādīti dažādi varbūtības aprēķini, izmantojot MS EXCEL funkcijas:
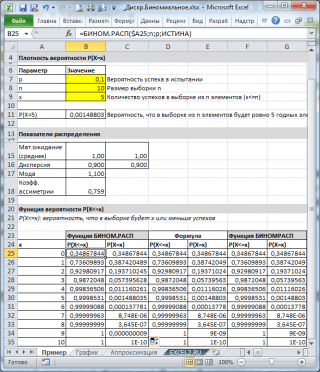
Kā redzams attēlā iepriekš, tiek pieņemts, ka:
- Bezgalīgā populācija, no kuras tiek veidota izlase, satur 10% (vai 0,1) labu elementu (parametru) lpp, trešās funkcijas arguments = BINOM.DIST() )
- Aprēķināt varbūtību, ka 10 elementu izlasē (parametrs n, funkcijas otrais arguments) būs tieši 5 derīgi elementi (pirmais arguments), jums jāuzraksta formula: =BINOM.DIST(5, 10, 0,1, FALSE)
- Pēdējais, ceturtais elements ir iestatīts = FALSE, t.i. tiek atgriezta funkcijas vērtība sadalījuma blīvums .
Ja ceturtā argumenta vērtība ir TRUE, tad funkcija BINOM.DIST() atgriež vērtību integrālā sadales funkcija vai vienkārši sadales funkcija. Šajā gadījumā var aprēķināt varbūtību, ka preču preču skaits izlasē būs no noteikta diapazona, piemēram, 2 vai mazāk (ieskaitot 0).
Lai to izdarītu, ierakstiet formulu: = BINOM.DIST(2, 10, 0,1, TRUE)
Piezīme: Ja x vērtība nav vesels skaitlis, . Piemēram, šādas formulas atgriezīs to pašu vērtību: =BINOM.DIST( 2 ; desmit; 0,1; TRUE)=BINOM.DIST( 2,9 ; desmit; 0,1; TRUE)
Piezīme: Piemēra failā varbūtības blīvums un sadales funkcija arī aprēķināts, izmantojot definīciju un COMBIN() funkciju.
Izplatības rādītāji
AT parauga fails uz lapas Piemērs Dažu sadalījuma rādītāju aprēķināšanai ir formulas:
- =n*p;
- (standarta novirze kvadrātā) = n*p*(1-p);
- = (n+1)*p;
- =(1-2*p)*SAKNE(n*p*(1-p)).
Mēs iegūstam formulu matemātiskās cerībasBinomiālais sadalījums izmantojot Bernulli shēma .
Pēc definīcijas nejaušs mainīgais X in Bernulli shēma(Bernulli gadījuma mainīgais) ir sadales funkcija :
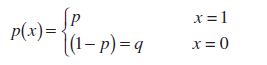
Šo sadalījumu sauc Bernulli izplatība .
Piezīme : Bernulli izplatība- īpašs gadījums Binomiālais sadalījums ar parametru n=1.
Ģenerēsim 3 masīvus no 100 skaitļiem ar dažādām veiksmes varbūtībām: 0,1; 0,5 un 0,9. Lai to izdarītu, logā Nejaušo skaitļu ģenerēšana iestatiet šādus parametrus katrai varbūtībai p:

Piezīme: ja iestatāt opciju Nejauši izkliede (Izlases sēkla), tad varat izvēlēties noteiktu nejaušu ģenerētu skaitļu kopu. Piemēram, iestatot šo opciju =25, jūs varat ģenerēt vienādas nejaušo skaitļu kopas dažādos datoros (ja, protams, citi sadalījuma parametri ir vienādi). Opcijas vērtība var būt vesela skaitļa vērtības no 1 līdz 32 767. Opcijas nosaukums Nejauši izkliede var sajaukt. Labāk būtu to tulkot kā Iestatiet numuru ar nejaušiem skaitļiem .
Rezultātā mums būs 3 kolonnas ar 100 skaitļiem, pamatojoties uz kuriem, piemēram, mēs varam novērtēt veiksmes varbūtību lpp pēc formulas: Panākumu skaits/100(cm. parauga faila lapa Bernulli ģenerēšana).

Piezīme: Priekš Bernulli sadalījumi ar p=0,5, varat izmantot formulu =RANDBETWEEN(0;1) , kas atbilst .
Nejaušo skaitļu ģenerēšana. Binomiālais sadalījums
Pieņemsim, ka paraugā ir 7 bojātas preces. Tas nozīmē, ka ir "ļoti iespējams", ka bojāto preču īpatsvars ir mainījies. lpp, kas ir mūsu ražošanas procesa īpašība. Lai gan šī situācija ir “ļoti iespējama”, pastāv iespēja (alfa risks, 1. tipa kļūda, “viltus trauksme”), ka lpp nemainījās, un palielinātais bojāto produktu skaits bija saistīts ar izlases veida atlasi.
Kā redzams attēlā zemāk, 7 ir bojāto produktu skaits, kas ir pieņemams procesam ar p=0,21 pie tādas pašas vērtības Alfa. Tas kalpo, lai ilustrētu, kad sliekšņa vērtība bojāti produkti paraugā, lpp"iespējams" palielinājās. Frāze "visticamāk" nozīmē, ka pastāv tikai 10% iespēja (100%-90%), ka defektīvo produktu procentuālā novirze virs sliekšņa ir tikai nejaušu iemeslu dēļ.
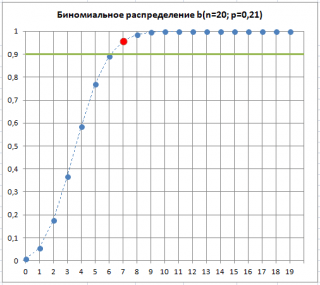
Tādējādi defektīvo produktu sliekšņa skaita pārsniegšana paraugā var kalpot kā signāls, ka process ir kļuvis satraukts un sācis ražot b par lielāks defektīvo produktu procentuālais daudzums.
Piezīme: Pirms MS EXCEL 2010 programmā EXCEL bija funkcija CRITBINOM() , kas ir līdzvērtīga BINOM.INV() . CRITBINOM() ir atstāts MS EXCEL 2010 un jaunākās versijās, lai nodrošinātu saderību.
Binomiālā sadalījuma saistība ar citiem sadalījumiem
Ja parametrs nBinomiālais sadalījums tiecas uz bezgalību un lpp mēdz uz 0, tad šajā gadījumā Binomiālais sadalījums var tuvināt. Ir iespējams formulēt nosacījumus, kad tuvinājums Poisson sadalījums darbojas labi:
- lpp(jo mazāk lpp un vēl n, jo precīzāks ir tuvinājums);
- lpp >0,9 (Ņemot vērā, ka q =1- lpp, aprēķini šajā gadījumā jāveic, izmantojot q(a X jāaizstāj ar n - x). Tāpēc, jo mazāk q un vēl n, jo precīzāka ir tuvinājums).
Pie 0.110 Binomiālais sadalījums var tuvināt.
Savukārt, Binomiālais sadalījums var kalpot kā labs tuvinājums, ja populācijas lielums ir N Hiperģeometriskais sadalījums daudz lielāks par izlases lielumu n (t.i., N>>n vai n/N Vairāk par augstākminēto sadalījumu saistību var lasīt rakstā. Tur ir doti arī aproksimācijas piemēri un izskaidroti nosacījumi, kad tas ir iespējams un ar kādu precizitāti.
PADOMS: Par citiem MS EXCEL izplatījumiem varat lasīt rakstā.
- (binomiālais sadalījums) Sadalījums, kas ļauj aprēķināt jebkura rašanās varbūtību nejaušs notikums, kas iegūts vairāku neatkarīgu notikumu novērojumu rezultātā, ja to veidojošās elementārās iestāšanās varbūtība ... ... Ekonomikas vārdnīca
- (Bernulli sadalījums) kāda notikuma atgadījumu skaita varbūtības sadalījums atkārtotos neatkarīgos izmēģinājumos, ja šī notikuma iestāšanās varbūtība katrā izmēģinājumā ir vienāda ar p(0 p 1). Tieši tā, numurs? ir šī notikuma gadījumi...... Lielā enciklopēdiskā vārdnīca
binomiālais sadalījums- - Telekomunikāciju tēmas, pamatjēdzieni EN binomiālais sadalījums ...
- (Bernulli sadalījums), kāda notikuma atgadījumu skaita varbūtības sadalījums atkārtotos neatkarīgos izmēģinājumos, ja šī notikuma iestāšanās varbūtība katrā izmēģinājumā ir p (0≤p≤1). Proti, šī notikuma gadījumu skaits μ… … enciklopēdiskā vārdnīca
binomiālais sadalījums- 1,49. Binomiālais sadalījums Diskrēta gadījuma lieluma X varbūtības sadalījums, ņemot jebkuru veselu skaitļu vērtības no 0 līdz n tā, ka x = 0, 1, 2, ..., n un parametriem n = 1, 2, ... un 0< p < 1, где Источник … Normatīvās un tehniskās dokumentācijas terminu vārdnīca-uzziņu grāmata
Bernulli sadalījums, gadījuma lieluma X varbūtības sadalījums, kas attiecīgi ņem veselus skaitļus ar varbūtībām (binomiālais koeficients; p parametrs B. R., ko sauc par pozitīva iznākuma varbūtību, kas ņem vērtības ... Matemātiskā enciklopēdija
Kāda notikuma gadījumu skaita varbūtības sadalījums atkārtotos neatkarīgos izmēģinājumos. Ja katrā izmēģinājumā notikuma iestāšanās varbūtība ir vienāda ar p un 0 ≤ p ≤ 1, tad šī notikuma atgadījumu skaits μ ar n neatkarīgu ... ... Lielā padomju enciklopēdija
- (Bernulli sadalījums), noteikta notikuma atgadījumu skaita varbūtības sadalījums atkārtotos neatkarīgos izmēģinājumos, ja šī notikuma iestāšanās varbūtība katrā izmēģinājumā ir p (0<или = p < или = 1). Именно, число м появлений … Dabaszinātnes. enciklopēdiskā vārdnīca
Binomiālais varbūtības sadalījums- (binomiālais sadalījums) Sadalījums, kas novērots gadījumos, kad katra neatkarīgā eksperimenta (statistiskā novērojuma) iznākumam ir viena no divām iespējamām vērtībām: uzvara vai sakāve, iekļaušana vai izslēgšana, plus vai ... Ekonomikas un matemātikas vārdnīca
Binomiālais varbūtības sadalījums- Sadalījums, kas tiek novērots gadījumos, kad katra neatkarīga eksperimenta (statistiskā novērojuma) iznākumam ir viena no divām iespējamām vērtībām: uzvara vai sakāve, iekļaušana vai izslēgšana, plus vai mīnus, 0 vai 1. Tas ir ... ... Tehniskā tulkotāja rokasgrāmata
Grāmatas
- Varbūtību teorija un matemātiskā statistika uzdevumos. Vairāk nekā 360 uzdevumu un vingrinājumu, D. A. Borzykh. Piedāvātā rokasgrāmata satur dažādas sarežģītības pakāpes uzdevumus. Tomēr galvenais uzsvars tiek likts uz vidējas sarežģītības uzdevumiem. Tas tiek darīts ar nolūku, lai mudinātu skolēnus…
- Varbūtību teorija un matemātiskā statistika uzdevumos Vairāk nekā 360 uzdevumu un vingrinājumu, Borzykh D. Piedāvātā rokasgrāmata satur dažādas sarežģītības pakāpes problēmas. Tomēr galvenais uzsvars tiek likts uz vidējas sarežģītības uzdevumiem. Tas tiek darīts ar nolūku, lai mudinātu skolēnus…
Sveiki! Mēs jau zinām, kas ir varbūtības sadalījums. Tas var būt diskrēts vai nepārtraukts, un mēs esam iemācījušies, ka to sauc par varbūtības blīvuma sadalījumu. Tagad izpētīsim dažus izplatītākus sadalījumus. Pieņemsim, ka man ir monēta un pareizā monēta, un es to apmetīšu 5 reizes. Definēšu arī gadījuma lielumu X, apzīmēšu ar lielo burtu X, tas būs vienāds ar "ērgļu" skaitu 5 metienos. Varbūt man ir 5 monētas, izmetīšu tās visas uzreiz un saskaitīšu, cik galvu saņēmu. Vai arī man varētu būt viena monēta, es varētu to uzsist 5 reizes un saskaitīt, cik reizes man ir galva. Tam īsti nav nozīmes. Bet pieņemsim, ka man ir viena monēta, un es to apmetu 5 reizes. Tad mums nebūs nekādas neskaidrības. Tātad šeit ir mana nejaušā mainīgā definīcija. Kā zināms, nejaušais mainīgais nedaudz atšķiras no parastā mainīgā, tas vairāk atgādina funkciju. Tas piešķir eksperimentam kādu vērtību. Un šis nejaušais mainīgais ir diezgan vienkāršs. Mēs vienkārši saskaitām, cik reižu “ērglis” izkrita pēc 5 metieniem - tas ir mūsu nejaušais lielums X. Padomāsim, kāda var būt dažādu vērtību varbūtība mūsu gadījumā? Tātad, kāda ir varbūtība, ka X (lielais X) ir 0? Tie. Kāda ir iespējamība, ka pēc 5 metieniem tas nekad neparādīsies? Nu, patiesībā tas ir tas pats, kas varbūtība iegūt dažas "astes" (pareizi, neliels pārskats par varbūtību teoriju). Jums vajadzētu iegūt dažas "astes". Kāda ir katras šīs "astes" iespējamība? Šī ir 1/2. Tie. tai vajadzētu būt 1/2 reizes 1/2, 1/2, 1/2 un vēlreiz 1/2. Tie. (1/2)⁵. 1⁵=1, dalīt ar 2⁵, t.i. pie 32. Diezgan loģiski. Tātad... Es mazliet atkārtošu to, ko mēs piedzīvojām varbūtības teorijā. Tas ir svarīgi, lai saprastu, kur mēs šobrīd virzāmies un kā patiesībā veidojas diskrētais varbūtību sadalījums. Tātad, kāda ir varbūtība, ka mēs saņemam galvu tieši vienu reizi? Nu, galvas varēja rasties pirmajā metienā. Tie. tas varētu būt šādi: "ērglis", "astes", "astes", "astes", "astes". Vai arī otrajā metienā var rasties galvas. Tie. varētu būt tāda kombinācija: "astes", "galvas", "astes", "astes", "astes" un tā tālāk. Viens "ērglis" varētu izkrist pēc jebkura no 5 metieniem. Kāda ir katras no šīm situācijām iespējamība? Varbūtība iegūt galvas ir 1/2. Tad varbūtība iegūt "astes", kas vienāda ar 1/2, tiek reizināta ar 1/2, ar 1/2, ar 1/2. Tie. katras no šīm situācijām varbūtība ir 1/32. Kā arī situācijas varbūtība, kad X=0. Faktiski jebkura īpaša galvas un astes secības varbūtība būs 1/32. Tātad šī iespējamība ir 1/32. Un tā varbūtība ir 1/32. Un šādas situācijas notiek tāpēc, ka “ērglis” var nokrist jebkurā no 5 metieniem. Tāpēc varbūtība, ka izkritīs tieši viens “ērglis”, ir vienāda ar 5 * 1/32, t.i. 5/32. Diezgan loģiski. Tagad sākas interesantais. Kāda ir varbūtība... (es uzrakstīšu katru piemēru citā krāsā)... kāda ir varbūtība, ka mans nejaušais mainīgais ir 2? Tie. Es metīšu monētu 5 reizes, un kāda ir iespējamība, ka tā nolaidīsies tieši ar galvām 2 reizes? Tas ir interesantāk, vai ne? Kādas kombinācijas ir iespējamas? Tās varētu būt galvas, galvas, astes, astes, astes. Tas varētu būt arī galvas, astes, galvas, astes, astes. Un, ja jūs domājat, ka šie divi “ērgļi” var stāvēt dažādās kombinācijas vietās, varat nedaudz apjukt. Jūs vairs nevarat domāt par izvietojumiem tā, kā mēs to darījām šeit iepriekš. Lai gan ... jūs varat, jūs tikai riskējat apjukt. Jums jāsaprot viena lieta. Katrai no šīm kombinācijām varbūtība ir 1/32. ½*½*½*½*½. Tie. katras no šīm kombinācijām varbūtība ir 1/32. Un mums vajadzētu padomāt, cik daudz tādu kombināciju pastāv, kas apmierina mūsu stāvokli (2 "ērgļi")? Tie. patiesībā jums ir jāiedomājas, ka ir 5 monētu mešanas, un jums ir jāizvēlas 2 no tiem, kuros “ērglis” izkrīt. Izliksimies, ka mūsu 5 metieni atrodas aplī, un arī iedomāsimies, ka mums ir tikai divi krēsli. Un mēs sakām: “Labi, kurš no jums sēdēs uz šiem Ērgļu krēsliem? Tie. kurš no jums būs "ērglis"? Un mūs neinteresē, kādā secībā viņi apsēžas. Es sniedzu šādu piemēru, cerot, ka tas jums būs skaidrāks. Un jūs varētu vēlēties noskatīties dažas varbūtības teorijas pamācības par šo tēmu, kad es runāju par Ņūtona binomiālu. Jo tur es iedziļināšos šajā visā sīkāk. Bet, ja jūs domājat šādi, jūs sapratīsit, kas ir binomiālais koeficients. Jo, ja jūs domājat šādi: Labi, man ir 5 metieni, kurš metiens piezemēs pirmās galvas? Tālāk ir norādītas 5 iespējas, kuru pārslēgšanu var iegūt pirmajās galvās. Un cik iespējas otram "ērglim"? Nu, pirmais metiens, ko jau izmantojām, atņēma vienu iespēju gūt galvu. Tie. vienu galvas pozīciju kombinācijā jau aizņem viens no metējiem. Tagad palikuši 4 metieni, kas nozīmē, ka otrs "ērglis" var uzkrist uz kāda no 4 metieniem. Un jūs to redzējāt tieši šeit. Es izvēlējos galvām 1. metienā un pieņēmu, ka 1 no 4 atlikušajiem metieniem arī galvām vajadzētu parādīties. Tātad šeit ir tikai 4 iespējas. Viss, ko es saku, ir tas, ka pirmajai galvai jums ir 5 dažādas pozīcijas, kurās tā var nolaisties. Un otrajam palikušas tikai 4 pozīcijas. Padomā par to. Kad mēs rēķinām šādi, tiek ņemts vērā pasūtījums. Bet mums tagad nav nozīmes tam, kādā secībā “galvas” un “astes” izkrīt. Mēs nesakām, ka tas ir "ērglis 1" vai ka tas ir "ērglis 2". Abos gadījumos tas ir tikai "ērglis". Mēs varētu pieņemt, ka šī ir 1. galva un šī ir 2. galva. Vai arī varētu būt otrādi: tas varētu būt otrais "ērglis", un šis ir "pirmais". Un es to saku, jo ir svarīgi saprast, kur izmantot izvietojumus un kur izmantot kombinācijas. Mūs neinteresē secība. Tātad patiesībā ir tikai 2 mūsu pasākuma izcelsmes veidi. Dalīsim to ar 2. Un, kā redzēsiet vēlāk, tas ir 2! mūsu pasākuma izcelsmes veidi. Ja būtu 3 galvas, tad būtu 3!, un es jums parādīšu, kāpēc. Tātad tas būtu... 5*4=20 dalīts ar 2 ir 10. Tātad ir 10 dažādas kombinācijas no 32, kur tev noteikti būs 2 galvas. Tātad 10*(1/32) ir vienāds ar 10/32, ko tas nozīmē? 5/16. Es rakstīšu caur binomiālo koeficientu. Šī ir vērtība šeit augšpusē. Ja padomājat, tas ir tas pats, kas 5! dalīts ar... Ko nozīmē šis 5 * 4? 5! ir 5*4*3*2*1. Tie. ja man te vajag tikai 5 * 4, tad šim es varu sadalīt 5! par 3! Tas ir vienāds ar 5*4*3*2*1, kas dalīts ar 3*2*1. Un paliek tikai 5 * 4. Tātad tas ir tāds pats kā šis skaitītājs. Un tad, jo mūs neinteresē secība, šeit vajag 2. Patiesībā 2!. Reiziniet ar 1/32. Tā būtu varbūtība, ka mēs trāpīsim tieši ar 2 galvām. Kāda ir varbūtība, ka mēs dabūsim galvas tieši 3 reizes? Tie. varbūtība, ka x=3. Tātad, pēc tās pašas loģikas, galviņas pirmo reizi var parādīties 1 no 5 apvērsumiem. Otrs galviņu gadījums var notikt 1 no 4 atlikušajiem metieniem. Un trešais galviņu gadījums var notikt 1 no 3 atlikušajiem metieniem. Cik dažādos veidos ir iespējams sakārtot 3 metienus? Kopumā, cik daudz veidu ir, kā sakārtot 3 objektus savās vietās? Tas ir 3! Un jūs varat to izdomāt vai arī vēlaties vēlreiz apskatīt apmācības, kurās es to paskaidroju sīkāk. Bet, ja ņem, piemēram, burtus A, B un C, tad ir 6 veidi, kā tos var sakārtot. Varat tos uzskatīt par virsrakstiem. Šeit varētu būt ACB, CAB. Varētu būt BAC, BCA un... Kāda ir pēdējā iespēja, kuru es nenosaucu? CBA. Ir 6 veidi, kā sakārtot 3 dažādus priekšmetus. Mēs dalām ar 6, jo mēs nevēlamies vēlreiz skaitīt šos 6 dažādos veidus, jo mēs tos traktējam kā līdzvērtīgus. Šeit mūs neinteresē kāds metienu skaits rezultēsies ar galvām. 5*4*3… To var pārrakstīt kā 5!/2!. Un sadaliet to ar vēl 3!. Tāds viņš ir. 3! vienāds ar 3*2*1. Trijatā sarūk. Tas kļūst par 2. Šis kļūst par 1. Vēlreiz 5*2, t.i. ir 10. Katras situācijas varbūtība ir 1/32, tātad šī atkal ir 5/16. Un tas ir interesanti. Varbūtība, ka jūs saņemsiet 3 galvas, ir tāda pati kā varbūtība, ka jūs saņemsiet 2 galvas. Un iemesls tam... Nu, ir daudz iemeslu, kāpēc tas notika. Bet, ja tā padomā, varbūtība iegūt 3 galvas ir tāda pati kā varbūtība iegūt 2 astes. Un varbūtībai iegūt 3 astes ir jābūt tādai pašai kā varbūtībai iegūt 2 galvas. Un labi, ka vērtības darbojas šādi. Labi. Kāda ir varbūtība, ka X=4? Mēs varam izmantot to pašu formulu, ko izmantojām iepriekš. Tas varētu būt 5*4*3*2. Tātad, šeit mēs rakstām 5 * 4 * 3 * 2 ... Cik dažādi veidi ir, kā sakārtot 4 objektus? Ir 4!. četri! - patiesībā šī ir šī daļa, tieši šeit. Tas ir 4*3*2*1. Tātad tas tiek atcelts, atstājot 5. Tad katrai kombinācijai ir 1/32 varbūtība. Tie. tas ir vienāds ar 5/32. Atkal ņemiet vērā, ka varbūtība, ka galviņas tiks iegūtas 4 reizes, ir vienāda ar varbūtību, ka galvas tiks paceltas 1 reizi. Un tam ir jēga, jo. 4 galvas ir tas pats, kas 1 aste. Teiksiet: nu un pie kādas mētāšanās šī “astes” izkritīs? Jā, tam ir 5 dažādas kombinācijas. Un katrai no tām varbūtība ir 1/32. Un visbeidzot, kāda ir varbūtība, ka X=5? Tie. paceļ galvu 5 reizes pēc kārtas. Tam vajadzētu būt šādam: "ērglis", "ērglis", "ērglis", "ērglis", "ērglis". Katras galvas varbūtība ir 1/2. Jūs tos reizinot un iegūstat 1/32. Jūs varat iet citu ceļu. Ja šajos eksperimentos ir 32 veidi, kā iegūt galvas un astes, tad šis ir tikai viens no tiem. Šeit bija 5 no 32 šādiem veidiem, šeit - 10 no 32. Tomēr mēs esam veikuši aprēķinus, un tagad esam gatavi sastādīt varbūtības sadalījumu. Bet mans laiks ir beidzies. Ļaujiet man turpināt nākamajā nodarbībā. Un ja ir noskaņojums, tad varbūt zīmē pirms nākamās nodarbības skatīšanās? Uz drīzu redzēšanos!
Šajā un nākamajās piezīmēs mēs aplūkosim nejaušu notikumu matemātiskos modeļus. Matemātiskais modelis ir matemātiska izteiksme, kas attēlo nejaušu mainīgo. Diskrētiem nejaušiem mainīgajiem šī matemātiskā izteiksme ir pazīstama kā sadalījuma funkcija.
Ja problēma ļauj skaidri uzrakstīt matemātisko izteiksmi, kas attēlo nejaušu mainīgo, varat aprēķināt precīzu jebkuras tā vērtības varbūtību. Šajā gadījumā jūs varat aprēķināt un uzskaitīt visas sadalījuma funkcijas vērtības. Uzņēmējdarbības, socioloģijas un medicīnas lietojumos ir dažādi nejaušo mainīgo sadalījumi. Viens no visnoderīgākajiem sadalījumiem ir binomiāls.
Binomiālais sadalījums tiek izmantots, lai modelētu situācijas, kuras raksturo šādas pazīmes.
- Izlase sastāv no noteikta elementu skaita n kas atspoguļo kāda testa rezultātu.
- Katrs parauga elements pieder vienai no divām savstarpēji izslēdzošām kategorijām, kas aptver visu parauga telpu. Parasti šīs divas kategorijas sauc par panākumiem un neveiksmēm.
- Panākumu iespējamība R ir nemainīgs. Tāpēc neveiksmes varbūtība ir 1. lpp.
- Jebkura izmēģinājuma iznākums (t.i., veiksme vai neveiksme) nav atkarīgs no cita izmēģinājuma iznākuma. Lai nodrošinātu rezultātu neatkarību, izlases vienumi parasti tiek iegūti, izmantojot divas dažādas metodes. Katrs izlases elements ir nejauši iegūts no bezgalīgas kopas bez aizstāšanas vai no ierobežotas kopas ar aizstāšanu.
Lejupielādējiet piezīmi formātā vai formātā, piemērus formātā
Binomiālo sadalījumu izmanto, lai novērtētu panākumu skaitu izlasē, kas sastāv no n novērojumiem. Kā piemēru ņemsim pasūtīšanu. Saxon Company klienti var izmantot interaktīvu elektronisku veidlapu, lai veiktu pasūtījumu un nosūtītu to uzņēmumam. Tad informācijas sistēma pārbauda, vai pasūtījumos nav kļūdu, kā arī nepilnīga vai neprecīza informācija. Jebkurš pasūtījums, par kuru rodas šaubas, tiek atzīmēts un iekļauts ikdienas izņēmumu pārskatā. Uzņēmuma apkopotie dati liecina, ka kļūdu iespējamība pasūtījumos ir 0,1. Uzņēmums vēlas uzzināt, kāda ir iespējamība atrast noteiktu skaitu kļūdainu pasūtījumu noteiktā paraugā. Piemēram, pieņemsim, ka klienti ir aizpildījuši četras elektroniskās veidlapas. Kāda ir iespējamība, ka visi pasūtījumi būs bez kļūdām? Kā aprēķināt šo varbūtību? Ar panākumiem mēs saprotam kļūdu, aizpildot veidlapu, un visus pārējos rezultātus uzskatīsim par neveiksmēm. Atgādiniet, ka mūs interesē kļūdaino pasūtījumu skaits konkrētajā paraugā.
Kādus rezultātus mēs varam novērot? Ja paraugs sastāv no četriem pasūtījumiem, viens, divi, trīs vai visi četri var būt nepareizi, turklāt visi var būt pareizi aizpildīti. Vai gadījuma lielums, kas apraksta nepareizi aizpildīto veidlapu skaitu, var iegūt kādu citu vērtību? Tas nav iespējams, jo nepareizi aizpildīto veidlapu skaits nevar pārsniegt izlases lielumu n vai būt negatīvam. Tādējādi gadījuma lielums, kas atbilst binomiālā sadalījuma likumam, ņem vērtības no 0 līdz n.
Pieņemsim, ka četru pasūtījumu izlasē tiek novēroti šādi rezultāti:
Kāda ir iespējamība atrast trīs kļūdainus pasūtījumus četru pasūtījumu izlasē un norādītajā secībā? Tā kā provizoriskie pētījumi ir parādījuši, ka kļūdas iespējamība, aizpildot veidlapu, ir 0,10, iepriekš minēto rezultātu iespējamību aprēķina šādi:
Tā kā rezultāti ir neatkarīgi viens no otra, norādītās iznākumu secības varbūtība ir vienāda ar: p*p*(1–p)*p = 0,1*0,1*0,9*0,1 = 0,0009. Ja nepieciešams aprēķināt izvēļu skaitu X n elementiem, jums jāizmanto kombinācijas formula (1):

kur n! \u003d n * (n -1) * (n - 2) * ... * 2 * 1 - skaitļa koeficients n, un 0! = 1 un 1! = 1 pēc definīcijas.
Šo izteicienu bieži dēvē par . Tādējādi, ja n = 4 un X = 3, secību skaitu, kas sastāv no trim elementiem, kas iegūti no 4 lieluma parauga, nosaka pēc šādas formulas:
Tāpēc trīs kļūdainu pasūtījumu atrašanas iespējamību aprēķina šādi:
(iespējamo secību skaits) *
(konkrētas secības varbūtība) = 4 * 0,0009 = 0,0036
Līdzīgi mēs varam aprēķināt varbūtību, ka no četriem pasūtījumiem viens vai divi ir nepareizi, kā arī varbūtību, ka visi pasūtījumi ir nepareizi vai visi ir pareizi. Tomēr, palielinoties izlases lielumam n kļūst grūtāk noteikt konkrētas rezultātu secības varbūtību. Šajā gadījumā jāpiemēro atbilstošs matemātiskais modelis, kas apraksta izvēļu skaita binomiālo sadalījumu X objekti no parauga, kas satur n elementi.
Binomiālais sadalījums

kur P(X)- varbūtība X panākumus noteiktam izlases lielumam n un veiksmes varbūtība R, X = 0, 1, … n.
Pievērsiet uzmanību faktam, ka formula (2) ir intuitīvu secinājumu formalizācija. Izlases vērtība X, ievērojot binomiālo sadalījumu, var iegūt jebkuru veselu skaitļu vērtību diapazonā no 0 līdz n. Darbs RX(1–p)n – X ir varbūtība noteiktai secībai, kas sastāv no X panākumi izlasē, kuru lielums ir vienāds ar n. Vērtība nosaka iespējamo kombināciju skaitu, kas sastāv no X panākumi iekšā n testiem. Tāpēc noteiktam izmēģinājumu skaitam n un veiksmes varbūtība R secības, kas sastāv no X veiksme ir vienāda ar
P(X) = (iespējamo secību skaits) * (konkrētas secības varbūtība) = 
Apsveriet piemērus, kas ilustrē formulas (2) piemērošanu.
1. Pieņemsim, ka nepareizas veidlapas aizpildīšanas varbūtība ir 0,1. Kāda ir varbūtība, ka trīs no četrām aizpildītajām veidlapām būs nepareizas? Izmantojot formulu (2), iegūstam, ka varbūtība atrast trīs kļūdainus pasūtījumus četru pasūtījumu izlasē ir vienāda ar
2. Pieņemsim, ka nepareizas veidlapas aizpildīšanas varbūtība ir 0,1. Kāda ir varbūtība, ka vismaz trīs no četrām aizpildītajām veidlapām būs nepareizas? Kā parādīts iepriekšējā piemērā, varbūtība, ka trīs no četrām aizpildītajām veidlapām būs nepareizas, ir 0,0036. Lai aprēķinātu varbūtību, ka vismaz trīs no četrām aizpildītajām veidlapām tiks aizpildītas nepareizi, jums jāpievieno iespējamība, ka no četrām aizpildītajām veidlapām trīs būs nepareizas, un varbūtība, ka no četrām aizpildītajām veidlapām visas būs nepareizas. Otrā notikuma varbūtība ir
Tādējādi varbūtība, ka no četrām aizpildītajām veidlapām vismaz trīs būs kļūdainas, ir vienāda ar
P(X > 3) = P(X = 3) + P(X = 4) = 0,0036 + 0,0001 = 0,0037
3. Pieņemsim, ka nepareizas veidlapas aizpildīšanas varbūtība ir 0,1. Kāda ir varbūtība, ka mazāk nekā trīs no četrām aizpildītajām veidlapām būs nepareizas? Šī notikuma varbūtība
P(X< 3) = P(X = 0) + P(X = 1) + P(X = 2)
Izmantojot formulu (2), mēs aprēķinām katru no šīm varbūtībām:

Tāpēc P(X< 3) = 0,6561 + 0,2916 + 0,0486 = 0,9963.
Varbūtība P(X< 3) можно вычислить иначе. Для этого воспользуемся тем, что событие X < 3 является дополнительным по отношению к событию Х>3. Pēc tam P(X< 3) = 1 – Р(Х> 3) = 1 – 0,0037 = 0,9963.
Pieaugot izlases lielumam n aprēķini, kas līdzīgi tiem, kas veikti 3. piemērā, kļūst sarežģīti. Lai izvairītos no šīm komplikācijām, daudzas binomiālās varbūtības tiek tabulas pirms laika. Dažas no šīm varbūtībām ir parādītas attēlā. 1. Piemēram, lai iegūtu varbūtību, ka X= 2 plkst n= 4 un lpp= 0,1, no tabulas jāizņem skaitlis līnijas krustpunktā X= 2 un kolonnas R = 0,1.

Rīsi. 1. Binomiālā varbūtība pie n = 4, X= 2 un R = 0,1
Binomiālo sadalījumu var aprēķināt, izmantojot Excel funkcijas=BINOM.DIST() (2. att.), kam ir 4 parametri: veiksmes skaits - X, izmēģinājumu skaits (vai izlases lielums) – n, veiksmes varbūtība ir R, parametrs neatņemama, kas ņem vērtības TRUE (šajā gadījumā tiek aprēķināta varbūtība vismaz X notikumi) vai FALSE (šajā gadījumā varbūtība tieši tā X notikumi).

Rīsi. 2. Funkcijas parametri =BINOM.DIST()
Iepriekšminētajiem trim piemēriem aprēķini ir parādīti attēlā. 3 (skatiet arī Excel failu). Katrā kolonnā ir viena formula. Cipari parāda atbildes uz atbilstošā skaitļa piemēriem).

Rīsi. 3. Binomiālā sadalījuma aprēķins programmā Excel n= 4 un lpp = 0,1
Binoma sadalījuma īpašības
Binomiālais sadalījums ir atkarīgs no parametriem n un R. Binomiālais sadalījums var būt simetrisks vai asimetrisks. Ja p = 0,05, binomiālais sadalījums ir simetrisks neatkarīgi no parametra vērtības n. Tomēr, ja p ≠ 0,05, sadalījums kļūst šķībs. Jo tuvāk parametra vērtība R līdz 0,05 un jo lielāks ir izlases lielums n, jo vājāka ir sadalījuma asimetrija. Tādējādi nepareizi aizpildīto veidlapu skaita sadalījums tiek nobīdīts pa labi, kopš lpp= 0,1 (4. att.).

Rīsi. 4. Binoma sadalījuma histogramma n= 4 un lpp = 0,1
Binomiālā sadalījuma matemātiskā cerība ir vienāds ar izlases lieluma reizinājumu n par veiksmes iespējamību R:
(3) M = E(X) =np
Vidēji ar pietiekami garu testu sēriju četru pasūtījumu izlasē var būt p \u003d E (X) \u003d 4 x 0,1 \u003d 0,4 nepareizi aizpildītas veidlapas.
Binomiālā sadalījuma standartnovirze
Piemēram, grāmatvedībā nepareizi aizpildīto veidlapu skaita standartnovirze informācijas sistēma vienāds:
Izmantoti materiāli no grāmatas Levins et al.Statistika vadītājiem. - M.: Williams, 2004. - lpp. 307–313
Protams, aprēķinot kumulatīvā sadalījuma funkciju, jāizmanto minētā attiecība starp binomiālo un beta sadalījumu. Šī metode noteikti ir labāka par tiešo summēšanu, ja n > 10.
Klasiskajās statistikas mācību grāmatās, lai iegūtu binomiālā sadalījuma vērtības, bieži tiek ieteikts izmantot formulas, kuru pamatā ir robežteorēmas (piemēram, Moivre-Laplasa formula). Jāpiebilst, ka no tīri skaitļošanas viedokļašo teorēmu vērtība ir tuvu nullei, it īpaši tagad, kad gandrīz uz katra galda ir jaudīgs dators. Iepriekš minēto tuvinājumu galvenais trūkums ir to pilnīgi nepietiekamā precizitāte n vērtībām, kas raksturīgas lielākajai daļai lietojumu. Ne mazāks trūkums ir skaidru ieteikumu trūkums par vienas vai otras tuvinājuma piemērojamību (standarta tekstos ir doti tikai asimptotiski formulējumi, tiem nav pievienoti precizitātes aprēķini, un tāpēc tie ir maz lietderīgi). Es teiktu, ka abas formulas ir derīgas tikai n< 200 и для совсем грубых, ориентировочных расчетов, причем делаемых “вручную” с помощью статистических таблиц. А вот связь между биномиальным распределением и бета-распределением позволяет вычислять биномиальное распределение достаточно экономно.
Es šeit neuzskatu kvantiļu atrašanas problēmu: diskrētiem sadalījumiem tas ir triviāls, un tajās problēmās, kurās rodas šādi sadalījumi, tas parasti nav aktuāls. Ja kvantiles joprojām ir nepieciešamas, es iesaku pārformulēt problēmu tā, lai strādātu ar p vērtībām (novērotajām nozīmībām). Šeit ir piemērs: realizējot dažus uzskaitīšanas algoritmus, katrā solī ir jāpārbauda statistiskā hipotēze par binomiālo gadījuma mainīgo. Saskaņā ar klasisko pieeju katrā solī ir jāaprēķina kritērija statistika un jāsalīdzina tā vērtība ar kritiskās kopas robežu. Tā kā algoritms tomēr ir uzskaitāms, kritiskās kopas robeža ir jānosaka katru reizi no jauna (galu galā izlases lielums mainās pa solim), kas neproduktīvi palielina laika izmaksas. Mūsdienu pieeja iesaka aprēķināt novēroto nozīmīgumu un salīdzināt to ar ticamības varbūtību, ietaupot uz kvantiļu meklēšanu.
Tāpēc šādi kodi neaprēķina apgriezto funkciju, tā vietā tiek dota funkcija rev_binomialDF, kas aprēķina veiksmes varbūtību p vienā izmēģinājumā, ņemot vērā izmēģinājumu skaitu n, veiksmes skaitu m un vērtību y iespējamību gūt šos m panākumus. Tas izmanto iepriekšminēto attiecību starp binomiālo un beta sadalījumu.
Faktiski šī funkcija ļauj iegūt ticamības intervālu robežas. Patiešām, pieņemsim, ka mēs gūstam m panākumus n binominālos izmēģinājumos. Kā zināms, parametra p divpusējā ticamības intervāla kreisā robeža ar ticamības līmeni ir 0, ja m = 0, un for ir vienādojuma atrisinājums  . Līdzīgi labā robeža ir 1, ja m = n, un for ir vienādojuma risinājums
. Līdzīgi labā robeža ir 1, ja m = n, un for ir vienādojuma risinājums  . Tas nozīmē, ka, lai atrastu kreiso robežu, mums ir jāatrisina vienādojums
. Tas nozīmē, ka, lai atrastu kreiso robežu, mums ir jāatrisina vienādojums  , un, lai meklētu pareizo - vienādojumu
, un, lai meklētu pareizo - vienādojumu  . Tie tiek atrisināti funkcijās binom_leftCI un binom_rightCI , kas attiecīgi atgriež divpusējā ticamības intervāla augšējo un apakšējo robežu.
. Tie tiek atrisināti funkcijās binom_leftCI un binom_rightCI , kas attiecīgi atgriež divpusējā ticamības intervāla augšējo un apakšējo robežu.
Es gribu atzīmēt, ka, ja nav nepieciešama absolūti neticama precizitāte, tad pietiekami lielam n var izmantot šādu tuvinājumu [B.L. van der Vērdens, Matemātiskā statistika. M: IL, 1960, Ch. 2, sek. 7]:  , kur g ir normālā sadalījuma kvantile. Šī tuvinājuma vērtība ir tāda, ka ir ļoti vienkārši tuvinājumi, kas ļauj aprēķināt normālā sadalījuma kvantiles (sk. tekstu par normālā sadalījuma aprēķināšanu un atbilstošo šīs atsauces sadaļu). Manā praksē (galvenokārt n > 100) šis tuvinājums deva apmēram 3-4 ciparus, kas, kā likums, ir pilnīgi pietiekami.
, kur g ir normālā sadalījuma kvantile. Šī tuvinājuma vērtība ir tāda, ka ir ļoti vienkārši tuvinājumi, kas ļauj aprēķināt normālā sadalījuma kvantiles (sk. tekstu par normālā sadalījuma aprēķināšanu un atbilstošo šīs atsauces sadaļu). Manā praksē (galvenokārt n > 100) šis tuvinājums deva apmēram 3-4 ciparus, kas, kā likums, ir pilnīgi pietiekami.
Aprēķiniem ar šādiem kodiem ir nepieciešami faili betaDF.h , betaDF.cpp (skatiet sadaļu par beta izplatīšanu), kā arī logGamma.h , logGamma.cpp (skatiet A pielikumu). Varat arī redzēt funkciju izmantošanas piemēru.
binomialDF.h failu
| #ifndef __BINOMIĀLS_H__ #include "betaDF.h" double binomialDF(dubultās pārbaudes, dubultie panākumi, dubultā p); /* * Lai ir neatkarīgu novērojumu "izmēģinājumi" * ar veiksmes varbūtību "p" katrā. * Aprēķiniet varbūtību B(veiksmes|mēģinājumi,p), ka veiksmes gadījumu skaits * ir no 0 līdz "veiksmēm" (ieskaitot). */ double rev_binomialDF(double izmēģinājumi, dubultie panākumi, dubultā y); /* * Lai Bernulli shēmas izmēģinājumos ir zināma vismaz m panākumu * varbūtība y. Funkcija atrod veiksmes varbūtību p * vienā izmēģinājumā. * * Aprēķinos tiek izmantota šāda sakarība * * 1 - p = rev_Beta(izmēģinājumi-veiksmi| panākumi+1, y). */ double binom_leftCI(dubultie izmēģinājumi, dubultie panākumi, dubults līmenis); /* Lai ir neatkarīgu novērojumu "pārbaudījumi" * ar veiksmes varbūtību "p" katrā * un veiksmes skaits ir "veiksmes". * Divpusējā ticamības intervāla * kreisā robeža tiek aprēķināta ar nozīmīguma līmeņa līmeni. */ double binom_rightCI(double n, dubultie panākumi, dubults līmenis); /* Lai ir neatkarīgu novērojumu "pārbaudījumi" * ar veiksmes varbūtību "p" katrā * un veiksmes skaits ir "veiksmes". * Divpusējā ticamības intervāla * labā robeža tiek aprēķināta ar nozīmīguma līmeņa līmeni. */ #endif /* Beidzas #ifndef __BINOMIAL_H__ */ |
binomialDF.cpp failu
| /**************************************************** **** **********/ /* Binomiālais sadalījums */ /******************************** ********************************/ #iekļauts |