พิจารณาการแจกแจงทวินาม คำนวณ มูลค่าที่คาดหวัง, การกระจายตัว, โหมด การใช้ฟังก์ชัน MS EXCEL BINOM.DIST() เราจะพล็อตฟังก์ชันการแจกแจงและกราฟความหนาแน่นของความน่าจะเป็น ให้เราประมาณค่าพารามิเตอร์การกระจาย p ความคาดหวังทางคณิตศาสตร์ของการแจกแจง และค่าเบี่ยงเบนมาตรฐาน พิจารณาการกระจายเบอร์นูลลีด้วย
คำนิยาม. ปล่อยให้พวกเขาถูกจัดขึ้น นการทดสอบโดยแต่ละเหตุการณ์สามารถเกิดขึ้นได้เพียง 2 เหตุการณ์เท่านั้น: เหตุการณ์ "สำเร็จ" ด้วยความน่าจะเป็น พี หรือเหตุการณ์ "ล้มเหลว" ที่มีความน่าจะเป็น q =1-p (สิ่งที่เรียกว่า โครงการเบอร์นูลลีเบอร์นูลลีการทดลอง).
ความน่าจะเป็นที่จะได้รับอย่างแน่นอน x ความสำเร็จเหล่านี้ น การทดสอบมีค่าเท่ากับ:
จำนวนความสำเร็จในกลุ่มตัวอย่าง x เป็นตัวแปรสุ่มที่มี การกระจายทวินาม(ภาษาอังกฤษ) ทวินามการกระจาย) พีและ น – เป็นพารามิเตอร์ของการแจกแจงนี้
จำได้ว่าตอนสมัคร แผนการของเบอร์นูลลีและเช่นเดียวกัน การกระจายทวินามต้องเป็นไปตามเงื่อนไขต่อไปนี้:
- การทดลองแต่ละครั้งต้องมีผลลัพธ์สองอย่างเท่านั้น ซึ่งเรียกว่า "ความสำเร็จ" และ "ความล้มเหลว" ตามเงื่อนไข
- ผลการทดสอบแต่ละครั้งไม่ควรขึ้นอยู่กับผลการทดสอบครั้งก่อน (การทดสอบอิสระ)
- โอกาสสำเร็จ พี ควรคงที่สำหรับการทดสอบทั้งหมด
การกระจายทวินามใน MS EXCEL
ใน MS EXCEL เริ่มตั้งแต่เวอร์ชัน 2010 สำหรับ มีฟังก์ชัน BINOM.DIST() ชื่อภาษาอังกฤษ- BINOM.DIST() ซึ่งให้คุณคำนวณความน่าจะเป็นที่กลุ่มตัวอย่างจะตรงกันทุกประการ X"ความสำเร็จ" (เช่น ฟังก์ชั่นความหนาแน่นของความน่าจะเป็น p(x) ดูสูตรด้านบน) และ ฟังก์ชันการกระจายอินทิกรัล(ความน่าจะเป็นที่กลุ่มตัวอย่างจะมี xหรือน้อยกว่า "ความสำเร็จ" รวมทั้ง 0)
ก่อนหน้า MS EXCEL 2010, EXCEL มีฟังก์ชัน BINOMDIST() ซึ่งช่วยให้คุณคำนวณได้ ฟังก์ชันการกระจายและ ความหนาแน่นของความน่าจะเป็นพี(x). BINOMDIST() ถูกทิ้งไว้ใน MS EXCEL 2010 เพื่อความเข้ากันได้
ไฟล์ตัวอย่างมีกราฟ ความหนาแน่นของการกระจายความน่าจะเป็นและ .

การกระจายทวินามมีนามว่า บี (น ; พี) .
บันทึก: สำหรับอาคาร ฟังก์ชันการกระจายอินทิกรัลแบบแผนภูมิพอดีตัว กำหนดการ, สำหรับ ความหนาแน่นของการกระจาย – ฮิสโตแกรมพร้อมการจัดกลุ่ม. สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการสร้างแผนภูมิ อ่านบทความประเภทหลักของแผนภูมิ
บันทึก: เพื่อความสะดวกในการเขียนสูตรในไฟล์ตัวอย่าง มีการสร้างชื่อสำหรับพารามิเตอร์แล้ว การกระจายทวินาม: น และ น.

ไฟล์ตัวอย่างแสดงการคำนวณความน่าจะเป็นต่างๆ โดยใช้ฟังก์ชัน MS EXCEL:
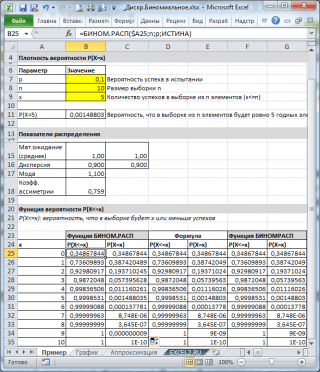
ดังที่เห็นในภาพด้านบน สันนิษฐานว่า:
- ประชากรอนันต์ที่สร้างตัวอย่างประกอบด้วยองค์ประกอบที่ดี 10% (หรือ 0.1) (พารามิเตอร์ พี, อาร์กิวเมนต์ฟังก์ชันที่สาม = BINOM.DIST() )
- เพื่อคำนวณความน่าจะเป็นที่ในกลุ่มตัวอย่าง 10 องค์ประกอบ (พารามิเตอร์ นอาร์กิวเมนต์ที่สองของฟังก์ชัน) จะมีองค์ประกอบที่ถูกต้อง 5 องค์ประกอบ (อาร์กิวเมนต์แรก) คุณต้องเขียนสูตร: =BINOM.DIST(5, 10, 0.1, เท็จ)
- องค์ประกอบสุดท้ายที่สี่ถูกตั้งค่า = FALSE นั่นคือ ค่าฟังก์ชันจะถูกส่งกลับ ความหนาแน่นของการกระจาย .
หากค่าของอาร์กิวเมนต์ที่สี่ = TRUE ฟังก์ชัน BINOM.DIST() จะส่งกลับค่า ฟังก์ชันการกระจายอินทิกรัลหรือง่ายๆ ฟังก์ชันการกระจาย. ในกรณีนี้ คุณสามารถคำนวณความน่าจะเป็นที่จำนวนของสินค้าที่ดีในกลุ่มตัวอย่างจะมาจากช่วงใดช่วงหนึ่ง เช่น 2 หรือน้อยกว่า (รวม 0)
เมื่อต้องการทำสิ่งนี้ ให้เขียนสูตร: = BINOM.DIST(2, 10, 0.1, ทรู)
บันทึก: สำหรับค่าที่ไม่ใช่จำนวนเต็มของ x, . ตัวอย่างเช่น สูตรต่อไปนี้จะคืนค่าเดิม: =BINOM.DIST( 2 ; สิบ; 0.1; จริง)=BINOM.DIST( 2,9 ; สิบ; 0.1; จริง)
บันทึก: ในไฟล์ตัวอย่าง ความหนาแน่นของความน่าจะเป็นและ ฟังก์ชันการกระจายยังคำนวณโดยใช้คำจำกัดความและฟังก์ชัน COMBIN()
ตัวชี้วัดการกระจาย
ที่ ไฟล์ตัวอย่างในชีต Exampleมีสูตรสำหรับคำนวณตัวบ่งชี้การกระจายบางตัว:
- =n*p;
- (ค่าเบี่ยงเบนมาตรฐานกำลังสอง) = n*p*(1-p);
- = (n+1)*p;
- =(1-2*p)*ROOT(n*p*(1-p)).
เราได้รับสูตร ความคาดหวังทางคณิตศาสตร์การกระจายทวินามโดยใช้ โครงการเบอร์นูลลี .
ตามคำจำกัดความ ตัวแปรสุ่ม X in โครงการเบอร์นูลลี(ตัวแปรสุ่มเบอร์นูลลี) has ฟังก์ชันการกระจาย :
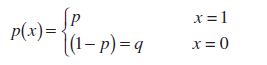
การกระจายนี้เรียกว่า การกระจายเบอร์นูลลี .
บันทึก : การกระจายเบอร์นูลลี- กรณีพิเศษ การกระจายทวินามด้วยพารามิเตอร์ n=1
มาสร้าง 3 อาร์เรย์ 100 ตัวเลขที่มีความน่าจะเป็นต่างกัน: 0.1; 0.5 และ 0.9 การทำเช่นนี้ในหน้าต่าง การสร้างตัวเลขสุ่มตั้งค่าพารามิเตอร์ต่อไปนี้สำหรับแต่ละความน่าจะเป็น p:

บันทึก: หากคุณตั้งค่าตัวเลือก สุ่มกระเจิง (สุ่มเมล็ด) จากนั้นคุณสามารถเลือกชุดตัวเลขที่สร้างขึ้นแบบสุ่มได้ ตัวอย่างเช่น โดยการตั้งค่าตัวเลือกนี้ =25 คุณสามารถสร้างชุดตัวเลขสุ่มชุดเดียวกันบนคอมพิวเตอร์เครื่องอื่นได้ (หากแน่นอน พารามิเตอร์การแจกแจงอื่นๆ เหมือนกัน) ค่าตัวเลือกสามารถใช้ค่าจำนวนเต็มได้ตั้งแต่ 1 ถึง 32,767 ชื่อตัวเลือก สุ่มกระเจิงสามารถสับสน จะดีกว่าถ้าแปลเป็น ตั้งตัวเลขด้วยตัวเลขสุ่ม .
ผลที่ได้คือเราจะมี 3 คอลัมน์ 100 ตัวเลข โดยอิงจากข้อมูลนั้น เช่น เราสามารถประมาณความน่าจะเป็นของความสำเร็จได้ พีตามสูตร: จำนวนความสำเร็จ/100(ซม. ไฟล์ตัวอย่าง การสร้าง Bernoulli).

บันทึก: สำหรับ การกระจายเบอร์นูลลีด้วย p=0.5 คุณสามารถใช้สูตร =RANDBETWEEN(0;1) ซึ่งสอดคล้องกับ
การสร้างตัวเลขสุ่ม การกระจายทวินาม
สมมติว่ามีสินค้าที่มีข้อบกพร่อง 7 รายการในตัวอย่างนี้ ซึ่งหมายความว่า "มีโอกาสมาก" ที่สัดส่วนของผลิตภัณฑ์ที่บกพร่องจะเปลี่ยนไป พีซึ่งเป็นลักษณะเฉพาะของกระบวนการผลิตของเรา แม้ว่าสถานการณ์นี้จะ "เป็นไปได้มาก" แต่ก็มีความเป็นไปได้ (ความเสี่ยงอัลฟา ข้อผิดพลาดประเภทที่ 1 "สัญญาณเตือนที่ผิดพลาด") ที่ พียังคงไม่เปลี่ยนแปลง และจำนวนสินค้าที่มีข้อบกพร่องเพิ่มขึ้นเกิดจากการสุ่มตัวอย่าง
ดังที่เห็นในรูปด้านล่าง 7 คือจำนวนสินค้าที่มีข้อบกพร่องที่ยอมรับได้สำหรับกระบวนการที่มีค่า p=0.21 ที่ค่าเท่ากัน อัลฟ่า. นี่แสดงให้เห็นว่าเมื่อ ค่าเกณฑ์ผลิตภัณฑ์ที่บกพร่องในตัวอย่าง พี“น่าจะ” เพิ่มขึ้น วลี "มีแนวโน้มมากที่สุด" หมายความว่ามีโอกาสเพียง 10% (100%-90%) ที่ความเบี่ยงเบนของเปอร์เซ็นต์ของผลิตภัณฑ์ที่มีข้อบกพร่องที่อยู่เหนือเกณฑ์นั้นเกิดจากสาเหตุแบบสุ่มเท่านั้น
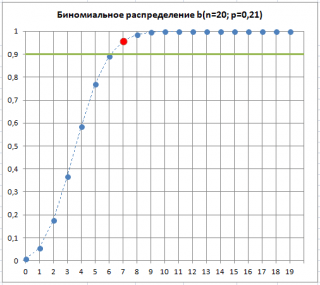
ดังนั้นการเกินจำนวนเกณฑ์ของผลิตภัณฑ์ที่มีข้อบกพร่องในตัวอย่างอาจเป็นสัญญาณว่ากระบวนการเกิดความไม่พอใจและเริ่มผลิตข เกี่ยวกับเปอร์เซ็นต์ของผลิตภัณฑ์ที่มีข้อบกพร่องสูงขึ้น
บันทึก: ก่อน MS EXCEL 2010, EXCEL มีฟังก์ชัน CRITBINOM() ซึ่งเทียบเท่ากับ BINOM.INV() CRITBINOM() เหลืออยู่ใน MS EXCEL 2010 และสูงกว่าสำหรับความเข้ากันได้
ความสัมพันธ์ของการแจกแจงทวินามกับการแจกแจงแบบอื่น
ถ้าพารามิเตอร์ นการกระจายทวินามมีแนวโน้มที่จะไม่มีที่สิ้นสุดและ พีมีแนวโน้มเป็น 0 ดังนั้นในกรณีนี้ การกระจายทวินามสามารถประมาณได้ เป็นไปได้ที่จะกำหนดเงื่อนไขเมื่อค่าประมาณ การกระจายปัวซองทำงานได้ดี:
- พี(น้อย พีและอื่น ๆ น, การประมาณที่แม่นยำยิ่งขึ้น);
- พี >0,9 (พิจารณาว่า q =1- พี, การคำนวณในกรณีนี้จะต้องดำเนินการโดยใช้ q(อา Xจะต้องถูกแทนที่ด้วย น - x). ดังนั้น ยิ่งน้อย qและอื่น ๆ นการประมาณค่าที่แม่นยำยิ่งขึ้น)
ที่ 0.110 การกระจายทวินามสามารถประมาณได้
ในทางกลับกัน การกระจายทวินามสามารถใช้เป็นค่าประมาณที่ดีเมื่อขนาดประชากรเป็น N การกระจายแบบไฮเปอร์เรขาคณิตใหญ่กว่าขนาดกลุ่มตัวอย่าง n มาก (เช่น N>>n หรือ n/N คุณสามารถอ่านเพิ่มเติมเกี่ยวกับความสัมพันธ์ของการแจกแจงข้างต้นได้ในบทความ นอกจากนี้ ยังมีตัวอย่างการประมาณค่าไว้ที่นั่น และจะมีการอธิบายเงื่อนไขเมื่อเป็นไปได้และ ด้วยความแม่นยำเพียงใด
คำแนะนำ: คุณสามารถอ่านเกี่ยวกับการแจกแจงอื่นๆ ของ MS EXCEL ได้ในบทความ
- (การแจกแจงทวินาม) การแจกแจงที่ให้คุณคำนวณความน่าจะเป็นของการเกิดใดๆ เหตุการณ์สุ่มได้จากการสังเกตเหตุการณ์อิสระจำนวนหนึ่งหากความน่าจะเป็นของการเกิดองค์ประกอบเบื้องต้น ... ... พจนานุกรมเศรษฐกิจ
- (การแจกแจงแบบเบอร์นูลลี) การแจกแจงความน่าจะเป็นของจำนวนครั้งของเหตุการณ์บางเหตุการณ์ในการทดลองอิสระซ้ำๆ หากความน่าจะเป็นที่จะเกิดขึ้นของเหตุการณ์นี้ในการทดลองแต่ละครั้งเท่ากับ p(0 p 1) ตรงเบอร์? มีเหตุการณ์นี้เกิดขึ้น ... ... พจนานุกรมสารานุกรมขนาดใหญ่
การกระจายทวินาม- - หัวข้อโทรคมนาคม แนวคิดพื้นฐาน EN การกระจายทวินาม ...
- (การแจกแจงแบบเบอร์นูลลี) การแจกแจงความน่าจะเป็นของจำนวนครั้งของเหตุการณ์บางเหตุการณ์ในการทดลองอิสระซ้ำๆ หากความน่าจะเป็นที่จะเกิดขึ้นของเหตุการณ์นี้ในการทดลองแต่ละครั้งคือ p (0≤p≤1) กล่าวคือ จำนวน μ ของเหตุการณ์ที่เกิดขึ้น… … พจนานุกรมสารานุกรม
การกระจายทวินาม- 1.49. การแจกแจงแบบทวินาม การแจกแจงความน่าจะเป็นของตัวแปรสุ่มแบบไม่ต่อเนื่อง X โดยนำค่าจำนวนเต็มใดๆ จาก 0 ถึง n เช่น นั้นสำหรับ x = 0, 1, 2, ..., n และพารามิเตอร์ n = 1, 2, ... และ 0< p < 1, где Источник … หนังสืออ้างอิงพจนานุกรมของข้อกำหนดของเอกสารเชิงบรรทัดฐานและทางเทคนิค
การแจกแจงแบบเบอร์นูลลี การแจกแจงความน่าจะเป็นของตัวแปรสุ่ม X ซึ่งรับค่าจำนวนเต็มที่มีความน่าจะเป็นตามลำดับ (ค่าสัมประสิทธิ์ทวินาม พารามิเตอร์ p B. R. เรียกว่าความน่าจะเป็นของผลลัพธ์ที่เป็นบวก ซึ่งใช้ค่า... สารานุกรมคณิตศาสตร์
การกระจายความน่าจะเป็นของจำนวนครั้งของเหตุการณ์บางเหตุการณ์ในการทดลองอิสระซ้ำๆ หากในการทดลองแต่ละครั้ง ความน่าจะเป็นของการเกิดเหตุการณ์มีค่าเท่ากับ p และ 0 ≤ p ≤ 1 ดังนั้นจำนวน μ ของเหตุการณ์นี้ที่มี n อิสระ ... ... สารานุกรมแห่งสหภาพโซเวียตผู้ยิ่งใหญ่
- (การแจกแจงแบบเบอร์นูลลี) การแจกแจงความน่าจะเป็นของจำนวนครั้งการเกิดเหตุการณ์หนึ่งในการทดลองอิสระซ้ำๆ หากความน่าจะเป็นของเหตุการณ์นี้ในการทดลองแต่ละครั้งเท่ากับ p (0<или = p < или = 1). Именно, число м появлений … วิทยาศาสตร์ธรรมชาติ. พจนานุกรมสารานุกรม
การแจกแจงความน่าจะเป็นแบบทวินาม- (การแจกแจงแบบทวินาม) การแจกแจงที่สังเกตพบในกรณีที่ผลลัพธ์ของการทดลองอิสระแต่ละครั้ง (การสังเกตทางสถิติ) ใช้ค่าใดค่าหนึ่งจากสองค่าที่เป็นไปได้: ชัยชนะหรือความพ่ายแพ้ การรวมหรือการยกเว้น บวกหรือ ... พจนานุกรมเศรษฐศาสตร์และคณิตศาสตร์
การแจกแจงความน่าจะเป็นแบบทวินาม- การกระจายที่สังเกตได้ในกรณีที่ผลลัพธ์ของการทดลองอิสระแต่ละครั้ง (การสังเกตทางสถิติ) ใช้ค่าใดค่าหนึ่งจากสองค่าที่เป็นไปได้: ชัยชนะหรือความพ่ายแพ้ การรวมหรือการยกเว้น บวกหรือลบ 0 หรือ 1 นั่นคือ ... ... คู่มือนักแปลทางเทคนิค
หนังสือ
- ทฤษฎีความน่าจะเป็นและสถิติทางคณิตศาสตร์ในปัญหา มากกว่า 360 งานและแบบฝึกหัด D.A. Borzykh คู่มือที่นำเสนอประกอบด้วยงานที่มีความซับซ้อนหลายระดับ อย่างไรก็ตาม เน้นหลักในงานที่มีความซับซ้อนปานกลาง จัดทำขึ้นโดยเจตนาเพื่อส่งเสริมให้นักเรียน...
- ทฤษฎีความน่าจะเป็นและสถิติทางคณิตศาสตร์ในปัญหา Borzykh D. ปัญหาและแบบฝึกหัดมากกว่า 360 รายการ คู่มือที่เสนอมีปัญหาระดับความซับซ้อนต่างๆ อย่างไรก็ตาม เน้นหลักในงานที่มีความซับซ้อนปานกลาง จัดทำขึ้นโดยเจตนาเพื่อส่งเสริมให้นักเรียน...
สวัสดี! เรารู้แล้วว่าการแจกแจงความน่าจะเป็นคืออะไร อาจเป็นแบบไม่ต่อเนื่องหรือต่อเนื่องก็ได้ และเราได้เรียนรู้ว่าสิ่งนี้เรียกว่าการแจกแจงความหนาแน่นของความน่าจะเป็น ตอนนี้ มาสำรวจการแจกแจงทั่วไปอีกสองสามแบบ สมมุติว่าผมมีเหรียญและเหรียญที่ถูกต้อง ผมจะพลิก 5 ครั้ง ฉันจะกำหนดตัวแปรสุ่ม X แทนด้วยตัวพิมพ์ใหญ่ X มันจะเท่ากับจำนวน "อินทรี" ในการโยน 5 ครั้ง บางทีฉันอาจมี 5 เหรียญ ฉันจะโยนมันทั้งหมดในคราวเดียวแล้วนับว่าฉันได้กี่หัว หรือผมมีเหรียญหนึ่งเหรียญก็ได้ พลิก 5 ครั้งแล้วนับว่าได้หัวกี่ครั้ง มันไม่สำคัญจริงๆ แต่สมมุติว่าผมมีเหรียญหนึ่งเหรียญและพลิกมัน 5 ครั้ง แล้วเราจะไม่มีความไม่แน่นอน นี่คือนิยามของตัวแปรสุ่มของฉัน อย่างที่เราทราบ ตัวแปรสุ่มนั้นแตกต่างจากตัวแปรปกติเล็กน้อย มันเหมือนกับฟังก์ชันมากกว่า มันกำหนดค่าบางอย่างให้กับการทดสอบ และตัวแปรสุ่มนี้ค่อนข้างง่าย เราแค่นับจำนวนครั้งที่ "อินทรี" หลุดออกมาหลังจากการโยน 5 ครั้ง - นี่คือตัวแปรสุ่มของเรา X ลองคิดถึงความน่าจะเป็นของค่าต่างๆ ในกรณีของเรา แล้วความน่าจะเป็นที่ X (ตัวพิมพ์ใหญ่ X) เป็น 0 เป็นเท่าไหร่? เหล่านั้น. ความน่าจะเป็นที่เมื่อโยน 5 ครั้งแล้วจะไม่ขึ้นหัวเป็นเท่าไหร่? อันที่จริง มันก็เหมือนกับความน่าจะเป็นที่จะได้ "ก้อย" บางอย่าง (ใช่แล้ว ภาพรวมเล็กๆ ของทฤษฎีความน่าจะเป็น) คุณควรได้รับ "หาง" บ้าง ความน่าจะเป็นของ "ก้อย" เหล่านี้คืออะไร? นี่คือ 1/2 เหล่านั้น. มันควรจะเป็น 1/2 คูณ 1/2, 1/2, 1/2 และ 1/2 อีกครั้ง เหล่านั้น. (1/2)⁵. 1⁵=1 หารด้วย 2⁵ นั่นคือ ที่ 32. ค่อนข้างมีเหตุผล ดังนั้น... ผมจะขอย้ำอีกครั้งว่าเราได้ทำอะไรบ้างเกี่ยวกับทฤษฎีความน่าจะเป็น นี่เป็นสิ่งสำคัญเพื่อทำความเข้าใจว่าขณะนี้เรากำลังเคลื่อนที่ไปที่ใด และในความเป็นจริง การแจกแจงความน่าจะเป็นแบบไม่ต่อเนื่องเกิดขึ้นได้อย่างไร แล้วความน่าจะเป็นที่เราจะได้หัวครั้งเดียวเป็นเท่าไหร่? หัวอาจจะโผล่ขึ้นมาในการโยนครั้งแรก เหล่านั้น. อาจเป็นดังนี้: "อินทรี" "ก้อย" "ก้อย" "ก้อย" "ก้อย" หรือหัวอาจโผล่ขึ้นมาในการโยนครั้งที่สอง เหล่านั้น. อาจมีการผสมผสานเช่น: "ก้อย", "หัว", "ก้อย", "ก้อย", "หาง" เป็นต้น "นกอินทรี" หนึ่งตัวอาจหลุดออกมาได้หลังจากโยน 5 ครั้ง ความน่าจะเป็นของแต่ละสถานการณ์เหล่านี้คืออะไร? ความน่าจะเป็นที่จะได้หัวคือ 1/2 จากนั้นความน่าจะเป็นที่จะได้ "ก้อย" เท่ากับ 1/2 จะถูกคูณด้วย 1/2 คูณ 1/2 ด้วย 1/2 เหล่านั้น. ความน่าจะเป็นของแต่ละสถานการณ์เหล่านี้คือ 1/32 เช่นเดียวกับความน่าจะเป็นของสถานการณ์ที่ X=0 อันที่จริง ความน่าจะเป็นของการเรียงลำดับหัวและก้อยพิเศษใดๆ จะเท่ากับ 1/32 ความน่าจะเป็นคือ 1/32 และความน่าจะเป็นของสิ่งนี้คือ 1/32 และสถานการณ์ดังกล่าวเกิดขึ้นเพราะ "นกอินทรี" อาจตกลงบนการโยนทั้ง 5 ครั้ง ดังนั้น ความน่าจะเป็นที่ “อินทรี” หนึ่งตัวจะหลุดออกมานั้นเท่ากับ 5 * 1/32 นั่นคือ 5/32. ค่อนข้างมีเหตุผล ตอนนี้ความน่าสนใจเริ่มต้นขึ้น ความน่าจะเป็น... (ฉันจะเขียนแต่ละตัวอย่างด้วยสีที่ต่างกัน)... ความน่าจะเป็นที่ตัวแปรสุ่มของฉันคือ 2 คืออะไร? เหล่านั้น. ฉันจะโยนเหรียญ 5 ครั้ง และความน่าจะเป็นที่จะโยนหัว 2 ครั้งเป็นเท่าไหร่? น่าสนใจกว่านี้ไหม? ชุดค่าผสมใดบ้างที่เป็นไปได้? อาจเป็นหัว หัว ก้อย ก้อย ก้อย มันอาจจะเป็นหัว ก้อย หัว ก้อย ก้อยก็ได้ และถ้าคุณคิดว่า "อินทรี" ทั้งสองนี้สามารถยืนอยู่ในที่ต่างๆ ของการรวมกัน คุณอาจสับสนเล็กน้อย คุณไม่สามารถนึกถึงตำแหน่งอย่างที่เราทำข้างต้นได้อีกต่อไป แม้ว่า ... คุณทำได้ แต่คุณเสี่ยงที่จะสับสนเท่านั้น คุณต้องเข้าใจสิ่งหนึ่ง สำหรับแต่ละชุดค่าผสมเหล่านี้ ความน่าจะเป็นคือ 1/32 ½*½*½*½*½. เหล่านั้น. ความน่าจะเป็นของแต่ละชุดค่าผสมเหล่านี้คือ 1/32 และเราควรคิดถึงจำนวนชุดค่าผสมดังกล่าวที่ตรงตามเงื่อนไขของเรา (2 "นกอินทรี") หรือไม่? เหล่านั้น. ที่จริงแล้ว คุณต้องจินตนาการว่ามีการโยนเหรียญ 5 ครั้ง และคุณต้องเลือก 2 อันที่ "นกอินทรี" หลุดออกมา สมมุติว่าเราโยน 5 ครั้งเป็นวงกลม ลองนึกภาพว่าเรามีเก้าอี้แค่สองตัว และเราพูดว่า: “เอาล่ะ พวกคุณคนไหนที่จะนั่งบนเก้าอี้เหล่านี้สำหรับ Eagles? เหล่านั้น. พวกคุณคนไหนจะเป็น "อินทรี"? และเราไม่สนใจในลำดับที่พวกเขานั่งลง ฉันยกตัวอย่างโดยหวังว่าจะชัดเจนสำหรับคุณ และคุณอาจต้องการดูบทแนะนำทฤษฎีความน่าจะเป็นในหัวข้อนี้ เมื่อฉันพูดถึงทวินามของนิวตัน เพราะฉันจะเจาะลึกทั้งหมดนี้ในรายละเอียดเพิ่มเติม แต่ถ้าคุณให้เหตุผลในลักษณะนี้ คุณจะเข้าใจว่าสัมประสิทธิ์ทวินามคืออะไร เพราะถ้าคุณคิดแบบนี้ โอเค ผมมี 5 ครั้ง การโยนครั้งไหนจะโยนหัวแรก? นี่คือความเป็นไปได้ 5 ประการที่การพลิกคว่ำจะทำให้หัวแรก และมีโอกาสมากแค่ไหนสำหรับ "นกอินทรี" ตัวที่สอง? การโยนครั้งแรกที่เราใช้ไปแล้วจะเสียโอกาสหัวไปหนึ่งลูก เหล่านั้น. ตำแหน่งหัวหน้าหนึ่งตำแหน่งในคอมโบถูกครอบครองโดยหนึ่งในทอย ตอนนี้เหลือ 4 ครั้ง ซึ่งหมายความว่า "นกอินทรี" ตัวที่สองสามารถตกลงบนหนึ่งใน 4 โยน และคุณเห็นมันตรงนี้ ฉันเลือกที่จะมีหัวในการโยนครั้งที่ 1 และคิดว่าในการโยน 1 ใน 4 ครั้งที่เหลือ การโยนหัวก็ควรจะโผล่ขึ้นมาเช่นกัน ดังนั้นมีความเป็นไปได้เพียง 4 เท่านั้นที่นี่ ทั้งหมดที่ฉันพูดคือสำหรับหัวแรก คุณมี 5 ตำแหน่งที่แตกต่างกัน มันสามารถลงจอดได้ และสำหรับคันที่ 2 เหลือเพียง 4 ตำแหน่งเท่านั้น คิดเกี่ยวกับมัน เมื่อเราคำนวณเช่นนี้ ลำดับจะถูกนำมาพิจารณา แต่สำหรับเราตอนนี้ ไม่สำคัญว่า "หัว" และ "ก้อย" จะหลุดออกมาในลำดับใด เราไม่ได้บอกว่ามันคือ "อินทรี 1" หรือว่า "อินทรี 2" ในทั้งสองกรณี เป็นเพียง "อินทรี" เราสามารถสมมติได้ว่านี่คือหัว 1 และนี่คือหัว 2 หรืออาจเป็นอย่างอื่นก็ได้ อาจเป็น "นกอินทรี" ตัวที่สอง และนี่คือ "ตัวแรก" และฉันพูดแบบนี้เพราะสิ่งสำคัญคือต้องเข้าใจว่าจะใช้ตำแหน่งใดและใช้ชุดค่าผสมที่ใด เราไม่สนใจลำดับ อันที่จริงแล้ว ที่มาของกิจกรรมของเรามีเพียง 2 วิธีเท่านั้น ลองหารมันด้วย 2 และอย่างที่คุณเห็นในภายหลัง มันคือ 2! ที่มาของกิจกรรมของเรา ถ้ามี 3 หัว มันก็มี 3 หัว! และผมจะแสดงให้คุณเห็นว่าทำไม นั่นก็คือ... 5*4=20 หารด้วย 2 ได้ 10 ดังนั้นจึงมีชุดค่าผสมต่างๆ 10 ชุดจาก 32 ชุดที่คุณจะมี 2 หัวอย่างแน่นอน 10*(1/32) เท่ากับ 10/32 มันเท่ากับอะไร? 5/16. ผมจะเขียนผ่านสัมประสิทธิ์ทวินาม นี่คือค่าที่ด้านบนสุด ถ้าลองคิดดูก็เท่ากับ 5! หารด้วย ... 5 * 4 นี่หมายความว่าอะไร? 5! คือ 5*4*3*2*1 เหล่านั้น. ถ้าฉันต้องการแค่ 5 * 4 ที่นี่ ฉันก็หาร 5 ได้! สำหรับ 3! เท่ากับ 5*4*3*2*1 หารด้วย 3*2*1 และเหลือเพียง 5*4 เท่านั้น มันก็เหมือนกับตัวเศษนี่ แล้วเพราะว่า เราไม่สนใจลำดับ เราต้องการ 2 ตรงนี้ จริงๆ แล้ว 2! คูณด้วย 1/32 นี่จะเป็นความน่าจะเป็นที่เราจะตีหัวได้ 2 หัวพอดี ความน่าจะเป็นที่เราจะได้หัว 3 ครั้งพอดีๆ เป็นเท่าไหร่? เหล่านั้น. ความน่าจะเป็นที่ x=3 ดังนั้น ด้วยตรรกะเดียวกัน การเกิดครั้งแรกของหัวอาจเกิดขึ้นในการพลิก 1 ใน 5 การโยนหัวครั้งที่สองอาจเกิดขึ้นใน 1 ใน 4 ครั้งที่เหลือ และการเกิดครั้งที่สามของศีรษะอาจเกิดขึ้นในการโยน 1 ใน 3 ครั้งที่เหลือ การจัดเรียง 3 ครั้งมีกี่วิธี? โดยทั่วไปมีกี่วิธีในการจัดเรียงวัตถุ 3 ชิ้นในตำแหน่งของพวกเขา? มัน 3! และคุณสามารถคิดออก หรือคุณอาจต้องการทบทวนบทช่วยสอนที่ฉันอธิบายรายละเอียดเพิ่มเติม แต่ถ้าคุณใช้ตัวอักษร A, B และ C เป็นต้น คุณสามารถจัดเรียงได้ 6 วิธี คุณสามารถคิดว่าสิ่งเหล่านี้เป็นหัวข้อ นี่อาจเป็น ACB, CAB อาจเป็น BAC, BCA และ... ตัวเลือกสุดท้ายที่ฉันไม่ได้ตั้งชื่อไว้คืออะไร ซีบีเอ. มี 6 วิธีในการจัดเรียง 3 รายการที่แตกต่างกัน เราหารด้วย 6 เพราะไม่อยากนับ 6 วิธีนั้นอีก เพราะเราถือว่ามันเท่ากัน ที่นี่เราไม่สนใจว่าจำนวนการโยนที่จะส่งผลให้หัว 5*4*3… สามารถเขียนใหม่เป็น 5!/2! แล้วหารอีก 3!. นี่คือสิ่งที่เขาเป็น 3! เท่ากับ 3*2*1 ทั้งสามกำลังหดตัว นี่กลายเป็น 2 นี่กลายเป็น 1 อีกครั้ง 5*2 นั่นคือ คือ 10 แต่ละสถานการณ์มีความน่าจะเป็น 1/32 ดังนั้นนี่คือ 5/16 อีกครั้ง และก็น่าสนใจ ความน่าจะเป็นที่คุณจะได้หัว 3 ตัว เท่ากับความน่าจะเป็นที่คุณจะได้หัว 2 ตัว และเหตุผลนั้น... มีหลายสาเหตุว่าทำไมมันถึงเกิดขึ้น แต่ถ้าคุณลองคิดดู ความน่าจะเป็นที่จะได้หัว 3 ครั้ง เท่ากับความน่าจะเป็นที่จะได้ 2 ก้อย และความน่าจะเป็นที่จะได้ 3 ก้อย ควรเท่ากับความน่าจะเป็นที่จะได้หัว 2 อัน และเป็นการดีที่ค่านิยมทำงานเช่นนี้ ดี. ความน่าจะเป็นที่ X=4 เป็นเท่าไหร่? เราสามารถใช้สูตรเดียวกับที่เราเคยใช้มาก่อน อาจเป็น 5*4*3*2 ในที่นี้เราเขียน 5 * 4 * 3 * 2 ... มีกี่วิธีในการจัดเรียงวัตถุ 4 ชิ้น? มัน 4!. สี่! - อันที่จริงนี่คือส่วนนี้ ตรงนี้ นี่คือ 4*3*2*1 นี่จึงหักล้าง เหลือ 5 จากนั้นแต่ละชุดค่าผสมจะมีความน่าจะเป็นเท่ากับ 1/32 เหล่านั้น. นี่เท่ากับ 5/32 ย้ำอีกครั้งว่าความน่าจะเป็นที่จะได้หัว 4 ครั้ง เท่ากับความน่าจะเป็นที่จะได้หัว 1 ครั้ง และมันก็สมเหตุสมผลเพราะ 4 หัว เท่ากับ 1 ก้อย คุณจะพูดว่า: แล้ว "หาง" ตัวนี้จะหลุดออกมาแบบไหน? ใช่ มี 5 ชุดค่าผสมที่แตกต่างกันสำหรับสิ่งนั้น และแต่ละอันมีความน่าจะเป็น 1/32 และสุดท้าย ความน่าจะเป็นที่ X=5 เป็นเท่าไหร่? เหล่านั้น. หัวขึ้น 5 ครั้งติดต่อกัน ควรเป็นดังนี้: "อินทรี", "อินทรี", "อินทรี", "อินทรี", "อินทรี" หัวแต่ละอันมีความน่าจะเป็น 1/2 คุณคูณมันแล้วได้ 1/32 คุณสามารถไปทางอื่นได้ หากมี 32 วิธีในการหาหัวและก้อยในการทดลองเหล่านี้ นี่เป็นเพียงหนึ่งในนั้น มี 5 วิธีจาก 32 วิธี ที่นี่ - 10 จาก 32 วิธี อย่างไรก็ตาม เราได้ดำเนินการคำนวณแล้ว และตอนนี้ เราพร้อมที่จะวาดการแจกแจงความน่าจะเป็นแล้ว แต่เวลาของฉันหมดแล้ว ให้ฉันดำเนินการในบทเรียนต่อไป และถ้าคุณกำลังมีอารมณ์ วาดรูปก่อนดูบทเรียนต่อไปไหม? พบกันเร็ว ๆ นี้!
ในบันทึกนี้และอีกสองสามข้อถัดไป เราจะพิจารณาแบบจำลองทางคณิตศาสตร์ของเหตุการณ์สุ่ม แบบจำลองทางคณิตศาสตร์เป็นนิพจน์ทางคณิตศาสตร์แทนตัวแปรสุ่ม สำหรับตัวแปรสุ่มแบบไม่ต่อเนื่อง นิพจน์ทางคณิตศาสตร์นี้เรียกว่าฟังก์ชันการกระจาย
หากปัญหาอนุญาตให้คุณเขียนนิพจน์ทางคณิตศาสตร์แทนตัวแปรสุ่มได้อย่างชัดเจน คุณสามารถคำนวณความน่าจะเป็นที่แน่นอนของค่าใดๆ ของมันได้ ในกรณีนี้ คุณสามารถคำนวณและแสดงรายการค่าทั้งหมดของฟังก์ชันการกระจายได้ ในการใช้งานทางธุรกิจ สังคมวิทยา และการแพทย์ มีการแจกแจงตัวแปรสุ่มต่างๆ การแจกแจงที่มีประโยชน์ที่สุดอย่างหนึ่งคือทวินาม
การกระจายทวินามใช้เพื่อจำลองสถานการณ์โดยมีลักษณะดังต่อไปนี้
- ตัวอย่างประกอบด้วยองค์ประกอบจำนวนคงที่ นแสดงถึงผลการทดสอบบางอย่าง
- แต่ละองค์ประกอบตัวอย่างเป็นของหนึ่งในสองหมวดหมู่ที่ไม่เกิดร่วมกันซึ่งครอบคลุมพื้นที่ตัวอย่างทั้งหมด โดยทั่วไปแล้ว ทั้งสองหมวดหมู่นี้เรียกว่าความสำเร็จและความล้มเหลว
- ความน่าจะเป็นของความสำเร็จ Rเป็นค่าคงที่ ดังนั้น ความน่าจะเป็นของความล้มเหลวคือ 1 - p.
- ผลลัพธ์ (เช่น สำเร็จหรือล้มเหลว) ของการทดลองใดๆ เป็นอิสระจากผลของการทดลองอื่น เพื่อให้แน่ใจว่าผลลัพธ์ที่เป็นอิสระ มักจะได้รายการตัวอย่างโดยใช้สองวิธีที่แตกต่างกัน แต่ละองค์ประกอบตัวอย่างจะถูกสุ่มมาจากประชากรที่ไม่มีที่สิ้นสุดโดยไม่มีการแทนที่หรือจากจำนวนประชากรจำกัดที่มีการแทนที่
ดาวน์โหลดบันทึกในรูปแบบหรือรูปแบบ ตัวอย่างในรูปแบบ
การแจกแจงทวินามใช้เพื่อประมาณจำนวนความสำเร็จในตัวอย่างที่ประกอบด้วย นการสังเกต ลองสั่งซื้อเป็นตัวอย่าง ลูกค้าของบริษัท Saxon สามารถใช้แบบฟอร์มอิเล็กทรอนิกส์แบบโต้ตอบเพื่อสั่งซื้อและส่งไปยังบริษัทได้ จากนั้นระบบข้อมูลจะตรวจสอบว่ามีข้อผิดพลาดในคำสั่งซื้อหรือไม่ รวมทั้งข้อมูลไม่ครบถ้วนหรือไม่ถูกต้อง ลำดับที่สงสัยจะถูกตั้งค่าสถานะและรวมอยู่ในรายงานข้อยกเว้นรายวัน ข้อมูลที่รวบรวมโดยบริษัทระบุว่าความน่าจะเป็นของข้อผิดพลาดในคำสั่งซื้อคือ 0.1 บริษัทต้องการทราบว่าความน่าจะเป็นที่จะพบคำสั่งซื้อที่ผิดพลาดจำนวนหนึ่งในกลุ่มตัวอย่างที่กำหนดเป็นเท่าใด ตัวอย่างเช่น สมมติว่าลูกค้ากรอกแบบฟอร์มอิเล็กทรอนิกส์สี่แบบฟอร์ม ความน่าจะเป็นที่คำสั่งซื้อทั้งหมดจะปราศจากข้อผิดพลาดเป็นเท่าใด วิธีการคำนวณความน่าจะเป็นนี้? โดยความสำเร็จ เราหมายถึงข้อผิดพลาดเมื่อกรอกแบบฟอร์ม และเราจะพิจารณาผลลัพธ์อื่น ๆ ทั้งหมดเป็นความล้มเหลว จำได้ว่าเราสนใจจำนวนคำสั่งซื้อที่ผิดพลาดในกลุ่มตัวอย่างที่กำหนด
เราสามารถสังเกตผลลัพธ์อะไรได้บ้าง? ถ้าตัวอย่างประกอบด้วยคำสั่งสี่คำสั่ง หนึ่ง สอง สามหรือทั้งสี่อาจผิด นอกจากนี้ ทั้งหมดอาจถูกกรอกอย่างถูกต้อง ตัวแปรสุ่มที่อธิบายจำนวนแบบฟอร์มที่กรอกไม่ถูกต้องสามารถใช้ค่าอื่นได้หรือไม่ เป็นไปไม่ได้เพราะจำนวนแบบฟอร์มที่กรอกไม่ถูกต้องต้องไม่เกินขนาดตัวอย่าง นหรือเป็นเชิงลบ ดังนั้นตัวแปรสุ่มที่ปฏิบัติตามกฎการแจกแจงทวินามจึงใช้ค่าตั้งแต่ 0 ถึง น.
สมมติว่าในตัวอย่างของคำสั่งสี่คำสั่ง สังเกตผลลัพธ์ต่อไปนี้:
ความน่าจะเป็นที่จะพบคำสั่งที่ผิดพลาดสามรายการในกลุ่มตัวอย่างสี่คำสั่งและในลำดับที่ระบุเป็นเท่าใด เนื่องจากการศึกษาเบื้องต้นแสดงให้เห็นว่าความน่าจะเป็นของข้อผิดพลาดในการกรอกแบบฟอร์มคือ 0.10 ความน่าจะเป็นของผลลัพธ์ข้างต้นจึงคำนวณได้ดังนี้
เนื่องจากผลลัพธ์เป็นอิสระจากกัน ความน่าจะเป็นของลำดับผลลัพธ์ที่ระบุจึงเท่ากับ: p*p*(1–p)*p = 0.1*0.1*0.9*0.1 = 0.0009 หากจำเป็นต้องคำนวณจำนวนตัวเลือก X นองค์ประกอบ คุณควรใช้สูตรผสม (1):

ที่ไหน n! \u003d n * (n -1) * (n - 2) * ... * 2 * 1 - แฟกทอเรียลของตัวเลข นและ 0! = 1 และ 1! = 1 ตามคำจำกัดความ
นิพจน์นี้มักถูกเรียกว่า ดังนั้น ถ้า n = 4 และ X = 3 จำนวนลำดับที่ประกอบด้วยสามองค์ประกอบที่ดึงมาจากตัวอย่างขนาด 4 จะได้รับโดยสูตรต่อไปนี้:
ดังนั้น ความน่าจะเป็นในการค้นหาคำสั่งที่ผิดพลาดสามคำสั่งจึงคำนวณได้ดังนี้
(จำนวนลำดับที่เป็นไปได้) *
(ความน่าจะเป็นของลำดับเฉพาะ) = 4 * 0.0009 = 0.0036
ในทำนองเดียวกัน เราสามารถคำนวณความน่าจะเป็นที่หนึ่งในสี่คำสั่งที่ไม่ถูกต้องหนึ่งหรือสองรายการ เช่นเดียวกับความน่าจะเป็นที่คำสั่งทั้งหมดไม่ถูกต้องหรือทั้งหมดถูกต้อง อย่างไรก็ตาม เมื่อขนาดกลุ่มตัวอย่างเพิ่มขึ้น นการกำหนดความน่าจะเป็นของลำดับผลลัพธ์นั้นยากขึ้น ในกรณีนี้ ควรใช้แบบจำลองทางคณิตศาสตร์ที่เหมาะสมซึ่งอธิบายการแจกแจงแบบทวินามของจำนวนตัวเลือก Xวัตถุจากตัวอย่างที่มี นองค์ประกอบ
การกระจายทวินาม

ที่ไหน พี(เอ็กซ์)- ความน่าจะเป็น Xความสำเร็จสำหรับขนาดตัวอย่างที่กำหนด นและความน่าจะเป็นของความสำเร็จ R, X = 0, 1, … น.
ให้ความสนใจกับความจริงที่ว่าสูตร (2) เป็นข้อสรุปที่เป็นทางการ ค่าสุ่ม Xการปฏิบัติตามการแจกแจงแบบทวินามสามารถรับค่าจำนวนเต็มใด ๆ ในช่วงตั้งแต่ 0 ถึง น. ทำงาน RX(1 - พี)น – Xคือความน่าจะเป็นของลำดับเฉพาะที่ประกอบด้วย Xความสำเร็จในกลุ่มตัวอย่างซึ่งมีขนาดเท่ากับ น. ค่ากำหนดจำนวนของชุดค่าผสมที่เป็นไปได้ซึ่งประกอบด้วย Xความสำเร็จใน นการทดสอบ ดังนั้นสำหรับการทดลองจำนวนหนึ่ง นและความน่าจะเป็นของความสำเร็จ Rความน่าจะเป็นของลำดับที่ประกอบด้วย Xความสำเร็จเท่ากับ
P(X) = (จำนวนลำดับที่เป็นไปได้) * (ความน่าจะเป็นของลำดับเฉพาะ) = 
พิจารณาตัวอย่างที่แสดงการใช้สูตร (2)
1. สมมติว่าความน่าจะเป็นของการกรอกแบบฟอร์มไม่ถูกต้องคือ 0.1 ความน่าจะเป็นที่แบบฟอร์มที่สมบูรณ์สามในสี่รูปแบบจะผิดคืออะไร? โดยใช้สูตร (2) เราได้รับว่าความน่าจะเป็นที่จะหาคำสั่งที่ผิดพลาดสามคำสั่งในกลุ่มตัวอย่างสี่คำสั่งมีค่าเท่ากับ
2. สมมติว่าความน่าจะเป็นที่จะกรอกแบบฟอร์มไม่ถูกต้องคือ 0.1 ความน่าจะเป็นที่แบบฟอร์มที่สมบูรณ์อย่างน้อยสามในสี่จะผิดเป็นเท่าใด ดังที่แสดงในตัวอย่างก่อนหน้านี้ ความน่าจะเป็นที่แบบฟอร์มที่สมบูรณ์สามในสี่รูปแบบจะไม่ถูกต้องคือ 0.0036 ในการคำนวณความน่าจะเป็นที่จะกรอกแบบฟอร์มที่กรอกอย่างไม่ถูกต้องอย่างน้อยสามในสี่แบบฟอร์ม คุณต้องเพิ่มความน่าจะเป็นที่ในแบบฟอร์มที่กรอกครบทั้งสี่แบบแล้วสามรายการจะไม่ถูกต้อง และความน่าจะเป็นที่แบบฟอร์มที่กรอกครบทั้งสี่รายการจะไม่ถูกต้อง ความน่าจะเป็นของเหตุการณ์ที่สองคือ
ดังนั้น ความน่าจะเป็นที่ในสี่รูปแบบที่กรอกแล้วอย่างน้อยสามรูปแบบจะผิดพลาดเท่ากับ
P(X > 3) = P(X = 3) + P(X = 4) = 0.0036 + 0.0001 = 0.0037
3. สมมติว่าความน่าจะเป็นที่จะกรอกแบบฟอร์มไม่ถูกต้องคือ 0.1 ความน่าจะเป็นที่แบบฟอร์มที่กรอกน้อยกว่าสามในสี่จะผิดเป็นเท่าใด ความน่าจะเป็นของเหตุการณ์นี้
P(X .)< 3) = P(X = 0) + P(X = 1) + P(X = 2)
โดยใช้สูตร (2) เราคำนวณความน่าจะเป็นแต่ละอย่างเหล่านี้:

ดังนั้น P(X< 3) = 0,6561 + 0,2916 + 0,0486 = 0,9963.
ความน่าจะเป็น P(X< 3) можно вычислить иначе. Для этого воспользуемся тем, что событие X < 3 является дополнительным по отношению к событию Х>3. จากนั้น P(X< 3) = 1 – Р(Х> 3) = 1 – 0,0037 = 0,9963.
เมื่อขนาดกลุ่มตัวอย่างเพิ่มขึ้น นการคำนวณที่คล้ายกับตัวอย่างที่ 3 กลายเป็นเรื่องยาก เพื่อหลีกเลี่ยงภาวะแทรกซ้อนเหล่านี้ ความน่าจะเป็นทวินามจำนวนมากจะถูกจัดตารางไว้ล่วงหน้า ความน่าจะเป็นเหล่านี้บางส่วนแสดงในรูปที่ 1. ตัวอย่างเช่น เพื่อให้ได้ความน่าจะเป็นที่ X= 2 ที่ น= 4 และ พี= 0.1 คุณควรแยกตัวเลขออกจากตารางที่จุดตัดของเส้น X= 2 และคอลัมน์ R = 0,1.

ข้าว. 1. ความน่าจะเป็นทวินามที่ น = 4, X= 2 และ R = 0,1
การแจกแจงทวินามสามารถคำนวณได้โดยใช้ ฟังก์ชัน Excel=BINOM.DIST() (รูปที่ 2) ซึ่งมี 4 พารามิเตอร์: จำนวนความสำเร็จ - X, จำนวนการทดลอง (หรือขนาดตัวอย่าง) – น, ความน่าจะเป็นของความสำเร็จคือ R, พารามิเตอร์ อินทิกรัลซึ่งรับค่า TRUE (ในกรณีนี้จะคำนวณความน่าจะเป็น อย่างน้อย Xเหตุการณ์) หรือ FALSE (ในกรณีนี้ ความน่าจะเป็นของ อย่างแน่นอน Xเหตุการณ์)

ข้าว. 2. พารามิเตอร์ฟังก์ชัน =BINOM.DIST()
สำหรับสามตัวอย่างข้างต้น การคำนวณจะแสดงในรูปที่ 3 (โปรดดูไฟล์ Excel ด้วย) แต่ละคอลัมน์มีหนึ่งสูตร ตัวเลขแสดงคำตอบของตัวอย่างตัวเลขที่เกี่ยวข้อง)

ข้าว. 3. การคำนวณการแจกแจงทวินามใน Excel for น= 4 และ พี = 0,1
คุณสมบัติของการกระจายทวินาม
การกระจายทวินามขึ้นอยู่กับพารามิเตอร์ นและ R. การกระจายแบบทวินามสามารถเป็นแบบสมมาตรหรือไม่สมมาตรก็ได้ ถ้า p = 0.05 การแจกแจงแบบทวินามจะสมมาตรโดยไม่คำนึงถึงค่าพารามิเตอร์ น. อย่างไรก็ตาม ถ้า p ≠ 0.05 การแจกแจงจะเบ้ ยิ่งค่าพารามิเตอร์ใกล้ขึ้น Rถึง 0.05 และยิ่งขนาดกลุ่มตัวอย่างใหญ่ขึ้น นที่อ่อนแอกว่าคือความไม่สมมาตรของการกระจาย ดังนั้นการกระจายจำนวนแบบฟอร์มที่กรอกไม่ถูกต้องจึงถูกเลื่อนไปทางขวาเนื่องจาก พี= 0.1 (รูปที่ 4).

ข้าว. 4. ฮิสโตแกรมของการแจกแจงทวินามสำหรับ น= 4 และ พี = 0,1
ความคาดหวังทางคณิตศาสตร์ของการแจกแจงทวินามเท่ากับผลคูณของขนาดตัวอย่าง นเกี่ยวกับความน่าจะเป็นของความสำเร็จ R:
(3) M = E(X) =np
โดยเฉลี่ยแล้วด้วยชุดการทดสอบที่ยาวเพียงพอในกลุ่มตัวอย่างสี่คำสั่ง อาจมี p \u003d E (X) \u003d 4 x 0.1 \u003d 0.4 แบบฟอร์มที่กรอกไม่ถูกต้อง
ค่าเบี่ยงเบนมาตรฐานการแจกแจงทวินาม
ตัวอย่างเช่น ค่าเบี่ยงเบนมาตรฐานของจำนวนแบบฟอร์มที่กรอกไม่ถูกต้องในการบัญชี ระบบข้อมูลเท่ากับ:
วัสดุจากหนังสือ Levin et al. ใช้สถิติสำหรับผู้จัดการ - ม.: วิลเลียมส์, 2547. - หน้า. 307–313
แน่นอน เมื่อคำนวณฟังก์ชันการแจกแจงสะสม เราควรใช้ความสัมพันธ์ที่กล่าวถึงระหว่างการแจกแจงทวินามและเบตา วิธีนี้ดีกว่าผลบวกโดยตรงเมื่อ n > 10
ในตำราคลาสสิกเกี่ยวกับสถิติ เพื่อให้ได้ค่าของการแจกแจงทวินาม มักแนะนำให้ใช้สูตรตามทฤษฎีบทจำกัด (เช่น สูตร Moivre-Laplace) ควรสังเกตว่า จากมุมมองของการคำนวณล้วนๆค่าของทฤษฎีบทเหล่านี้เกือบเป็นศูนย์ โดยเฉพาะตอนนี้ เมื่อมีคอมพิวเตอร์ทรงพลังในแทบทุกโต๊ะ ข้อเสียเปรียบหลักของการประมาณข้างต้นคือความแม่นยำไม่เพียงพออย่างสมบูรณ์สำหรับค่า n ทั่วไปสำหรับการใช้งานส่วนใหญ่ ข้อเสียไม่น้อยคือการไม่มีคำแนะนำที่ชัดเจนเกี่ยวกับการบังคับใช้ของการประมาณอย่างใดอย่างหนึ่ง (เฉพาะสูตรเชิงซีมโทติกเท่านั้นที่ให้ไว้ในข้อความมาตรฐาน ไม่มีการประมาณค่าความแม่นยำ ดังนั้นจึงมีประโยชน์เพียงเล็กน้อย) ฉันจะบอกว่าทั้งสองสูตรใช้ได้เฉพาะกับ n< 200 и для совсем грубых, ориентировочных расчетов, причем делаемых “вручную” с помощью статистических таблиц. А вот связь между биномиальным распределением и бета-распределением позволяет вычислять биномиальное распределение достаточно экономно.
ฉันไม่ได้พิจารณาถึงปัญหาในการค้นหาควอนไทล์: สำหรับการแจกแจงแบบไม่ต่อเนื่องนั้นเป็นเรื่องเล็กน้อย และในปัญหาเหล่านั้นที่การแจกแจงดังกล่าวเกิดขึ้น ตามกฎแล้วจะไม่เกี่ยวข้อง หากยังต้องการควอนไทล์ ผมขอแนะนำให้จัดรูปแบบปัญหาใหม่ในลักษณะที่จะทำงานกับค่า p (สังเกตนัยสำคัญ) นี่คือตัวอย่าง: เมื่อใช้อัลกอริธึมการแจงนับ ในแต่ละขั้นตอน จะต้องตรวจสอบสมมติฐานทางสถิติเกี่ยวกับตัวแปรสุ่มทวินาม ตามแนวทางคลาสสิก ในแต่ละขั้นตอน จำเป็นต้องคำนวณสถิติของเกณฑ์และเปรียบเทียบค่ากับขอบเขตของชุดวิกฤต อย่างไรก็ตาม เนื่องจากอัลกอริธึมมีการแจกแจงนับ จึงจำเป็นต้องกำหนดขอบเขตของชุดวิกฤติในแต่ละครั้งอีกครั้ง (หลังจากทั้งหมด ขนาดกลุ่มตัวอย่างจะเปลี่ยนจากขั้นตอนหนึ่งไปอีกขั้น) ซึ่งทำให้ต้นทุนเวลาเพิ่มขึ้นอย่างไม่เกิดผล วิธีการสมัยใหม่แนะนำให้คำนวณนัยสำคัญที่สังเกตได้และเปรียบเทียบกับความน่าจะเป็นของความเชื่อมั่น ประหยัดในการค้นหาควอนไทล์
ดังนั้น รหัสต่อไปนี้จะไม่คำนวณฟังก์ชันผกผัน แต่ให้ฟังก์ชัน rev_binomialDF ซึ่งคำนวณความน่าจะเป็น p ของความสำเร็จในการทดลองครั้งเดียวโดยพิจารณาจากจำนวน n ของการทดลอง จำนวน m ของความสำเร็จในนั้น และค่า y ของความน่าจะเป็นที่จะสำเร็จ m เหล่านี้ สิ่งนี้ใช้ความสัมพันธ์ดังกล่าวระหว่างการแจกแจงทวินามและเบต้า
อันที่จริง ฟังก์ชันนี้ช่วยให้คุณได้รับขอบเขตของช่วงความเชื่อมั่น อันที่จริง สมมติว่าเราประสบความสำเร็จ m ในการทดลองแบบทวินาม n ครั้ง ดังที่ทราบ ขอบซ้ายของช่วงความเชื่อมั่นสองด้านสำหรับพารามิเตอร์ p ที่มีระดับความเชื่อมั่นคือ 0 ถ้า m = 0 และ for คือคำตอบของสมการ  . ในทำนองเดียวกัน ขอบขวาคือ 1 ถ้า m = n และ for คือคำตอบของสมการ
. ในทำนองเดียวกัน ขอบขวาคือ 1 ถ้า m = n และ for คือคำตอบของสมการ  . นี่หมายความว่าในการหาขอบด้านซ้าย เราต้องแก้สมการ
. นี่หมายความว่าในการหาขอบด้านซ้าย เราต้องแก้สมการ  และเพื่อค้นหาสิ่งที่ถูกต้อง - สมการ
และเพื่อค้นหาสิ่งที่ถูกต้อง - สมการ  . พวกเขาได้รับการแก้ไขในฟังก์ชัน binom_leftCI และ binom_rightCI ซึ่งส่งคืนขอบเขตบนและล่างของช่วงความมั่นใจสองด้านตามลำดับ
. พวกเขาได้รับการแก้ไขในฟังก์ชัน binom_leftCI และ binom_rightCI ซึ่งส่งคืนขอบเขตบนและล่างของช่วงความมั่นใจสองด้านตามลำดับ
ฉันต้องการทราบว่าหากไม่ต้องการความแม่นยำที่น่าเหลือเชื่ออย่างยิ่ง ดังนั้นสำหรับ n ที่มีขนาดใหญ่เพียงพอ คุณสามารถใช้ค่าประมาณต่อไปนี้ [B.L. van der Waerden สถิติทางคณิตศาสตร์ ม: อิลลินอยส์, 1960, Ch. 2 วินาที 7]:  โดยที่ g คือควอนไทล์ของการแจกแจงแบบปกติ ค่าของการประมาณนี้คือมีการประมาณที่ง่ายมากที่ช่วยให้คุณสามารถคำนวณควอนไทล์ของการแจกแจงแบบปกติ (ดูข้อความเกี่ยวกับการคำนวณการแจกแจงแบบปกติและส่วนที่เกี่ยวข้องของข้อมูลอ้างอิงนี้) ในทางปฏิบัติของฉัน (ส่วนใหญ่สำหรับ n > 100) การประมาณนี้ให้ตัวเลขประมาณ 3-4 หลักซึ่งตามกฎก็เพียงพอแล้ว
โดยที่ g คือควอนไทล์ของการแจกแจงแบบปกติ ค่าของการประมาณนี้คือมีการประมาณที่ง่ายมากที่ช่วยให้คุณสามารถคำนวณควอนไทล์ของการแจกแจงแบบปกติ (ดูข้อความเกี่ยวกับการคำนวณการแจกแจงแบบปกติและส่วนที่เกี่ยวข้องของข้อมูลอ้างอิงนี้) ในทางปฏิบัติของฉัน (ส่วนใหญ่สำหรับ n > 100) การประมาณนี้ให้ตัวเลขประมาณ 3-4 หลักซึ่งตามกฎก็เพียงพอแล้ว
การคำนวณด้วยรหัสต่อไปนี้ต้องใช้ไฟล์ betaDF.h , betaDF.cpp (ดูหัวข้อเกี่ยวกับการแจกจ่ายเบต้า) รวมถึง logGamma.h , logGamma.cpp (ดูภาคผนวก A) คุณยังสามารถดูตัวอย่างการใช้ฟังก์ชันได้อีกด้วย
ไฟล์ทวินามDF.h
| #ifndef __BINOMIAL_H__ #include "betaDF.h" double binomialDF (การทดลองสองครั้ง ความสำเร็จสองครั้ง double p); /* * ให้มี "การทดลอง" ของการสังเกตอิสระ * ด้วยความน่าจะเป็น "p" ของความสำเร็จในแต่ละครั้ง * คำนวณความน่าจะเป็น B(successes|trials,p) ที่จำนวน * ของความสำเร็จอยู่ระหว่าง 0 และ "successes" (รวม) */ double rev_binomialDF (การทดลองสองครั้ง, ความสำเร็จสองครั้ง, สองเท่า y); /* * ให้ความน่าจะเป็น y ของความสำเร็จอย่างน้อย m * เป็นที่ทราบในการทดลองของโครงการ Bernoulli ฟังก์ชันค้นหาความน่าจะเป็น p * ของความสำเร็จในการทดลองครั้งเดียว * * ความสัมพันธ์ต่อไปนี้ใช้ในการคำนวณ * * 1 - p = rev_Beta(trials-successes| successes+1, y) */ double binom_leftCI (การทดลองสองครั้ง, ความสำเร็จสองครั้ง, ระดับสองเท่า); /* ให้มี "การทดลอง" ของการสังเกตอิสระ * ด้วยความน่าจะเป็น "p" ของความสำเร็จในแต่ละ * และจำนวนความสำเร็จคือ "ความสำเร็จ" * ขอบซ้ายของช่วงความเชื่อมั่นสองด้าน * คำนวณด้วยระดับนัยสำคัญ */ double binom_rightCI(double n, double success, double level); /* ให้มี "การทดลอง" ของการสังเกตอิสระ * ด้วยความน่าจะเป็น "p" ของความสำเร็จในแต่ละ * และจำนวนความสำเร็จคือ "ความสำเร็จ" * ขอบเขตด้านขวาของช่วงความเชื่อมั่นสองด้าน * คำนวณด้วยระดับนัยสำคัญ */ #endif /* สิ้นสุด #ifndef __BINOMIAL_H__ */ |
ไฟล์ทวินามDF.cpp
| /****************************************************** **** **********/ /* การกระจายทวินาม */ /****************************** **** *********************************/ #include |